在 Amazon SageMaker 上进行LLM大语言模型训练
在 Amazon SageMaker 上进行LLM大语言模型训练
本文档旨在为在 Amazon SageMaker 平台进行大规模语言模型(LLM)训练提供一套全面的最佳实践指南。内容涵盖从技术原理、应用场景到实际生产落地中需要考虑的计算、存储、网络、弹性等关键环节,并提供必要的参考资料和常见问题解答。
1. 技术原理与应用场景
1.1 大型语言模型(LLM)概述
语言模型是利用统计方法预测文本序列中后续词元(token)的概率模型。大型语言模型(LLM)是基于神经网络的语言模型,其参数量可达数亿(如 BERT)甚至超过万亿(如 MiCS)。由于其庞大的规模,单个 GPU 的训练已变得不切实际。LLM 强大的文本生成能力使其在文本合成、摘要、机器翻译等领域备受欢迎。
LLM 的模型大小和训练数据量是一把双刃剑:它带来了卓越的建模质量,但同时也引发了严峻的基础设施挑战。模型本身通常过大,无法装入单个 GPU 设备的内存,甚至无法装入单个多 GPU 服务器的所有设备中。这些因素要求 LLM 的训练必须在由大量加速计算实例组成的大规模集群上进行。
1.2 Amazon SageMaker 训练平台
Amazon SageMaker 是一个托管的批量机器学习计算服务,它通过消除基础设施管理的复杂性,显著缩短了大规模模型训练和调优的时间与成本。用户仅需一个启动命令,Amazon SageMaker 即可启动一个功能齐全的、临时的计算集群来运行指定的任务,并提供元数据存储、托管 I/O 和分布式计算等增强的机器学习功能。
1.3 核心技术原理:3D 并行训练
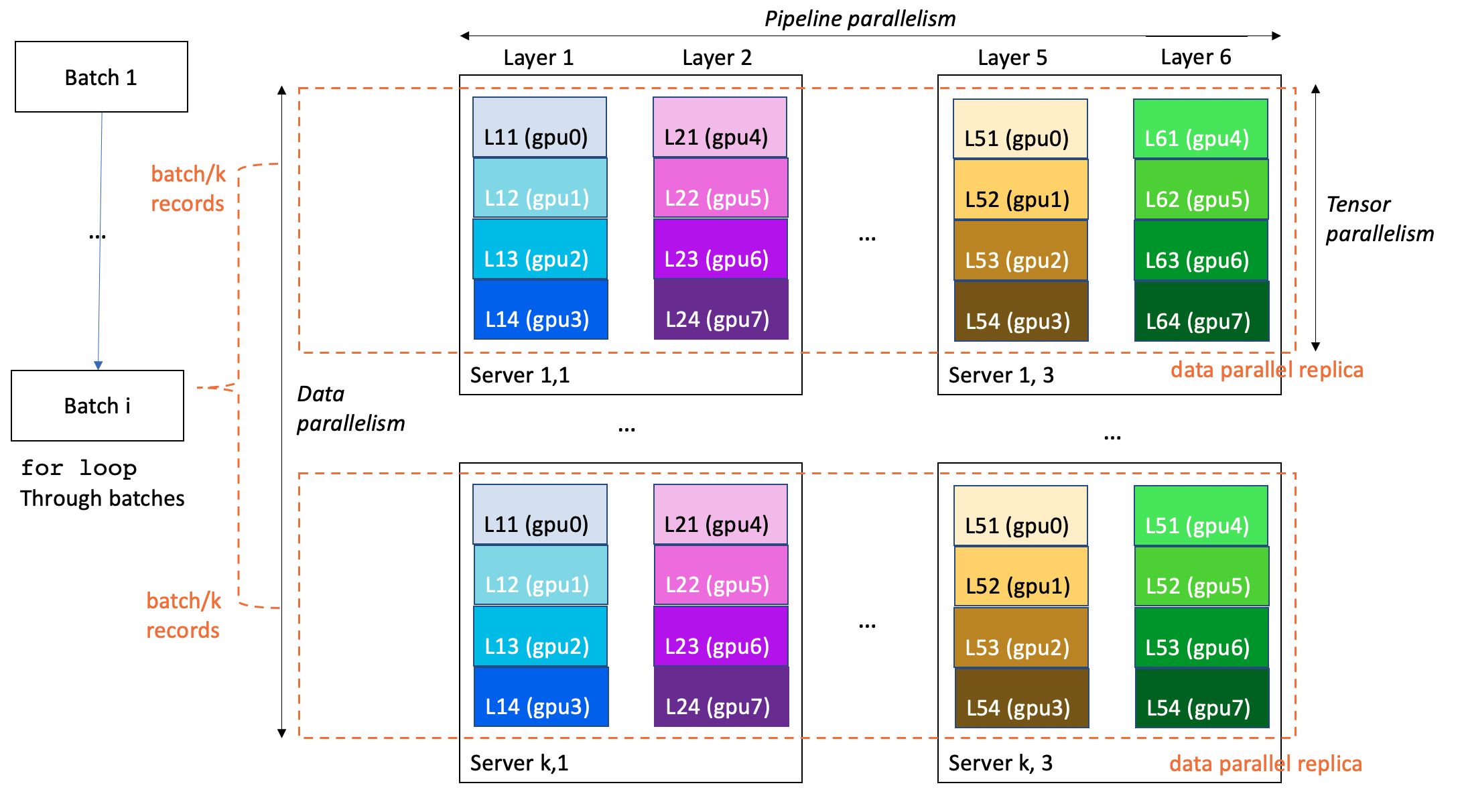
为了有效训练 LLM,业界通常采用 3D 并行(3D Parallelism) 策略,将训练任务分解到集群的多个 GPU 上。SageMaker 通过其分布式训练库,为这些并行策略提供了原生且优化的支持。
- 数据并行(Data Parallelism): 将训练数据的小批量(mini-batches)分割并分发给模型的多个相同副本,以提高处理速度。
- 流水线并行(Pipeline Parallelism): 将模型的不同层(layers)分配给不同的 GPU 甚至不同的实例,从而使模型大小能够超越单个 GPU 或单个服务器的限制。
- 张量并行(Tensor Parallelism): 将单个模型层分割到多个 GPU 上(通常在同一台服务器内),以支持单个层的大小超过单个 GPU 的限制。
下图展示了一个在 k*3 台服务器(每台服务器 8 个 GPU)上训练一个 6 层模型的 3D 并行训练示例。数据并行度为 k,流水线并行度为 6,张量并行度为 4。集群中的每个 GPU 包含模型层的四分之一,一个完整的模型被分区到三台服务器上(共 24 个 GPU)。
1.4 核心技术原理:高性能网络通信
大规模分布式训练的性能瓶颈往往在于节点间的通信效率。SageMaker 利用以下关键技术来确保低延迟、高带宽的通信。
1.4.1 EFA 深度解析
Elastic Fabric Adapter (EFA) 是一种可附加到 Amazon EC2 实例的网络设备,旨在加速高性能计算 (HPC)、机器学习 (ML) 和人工智能 (AI) 应用。它旨在提供可与本地集群相媲美的应用性能,同时兼具云的弹性与可扩展性。与云环境中传统的 TCP 传输相比,EFA 提供更低且更一致的延迟以及更高的吞吐量。
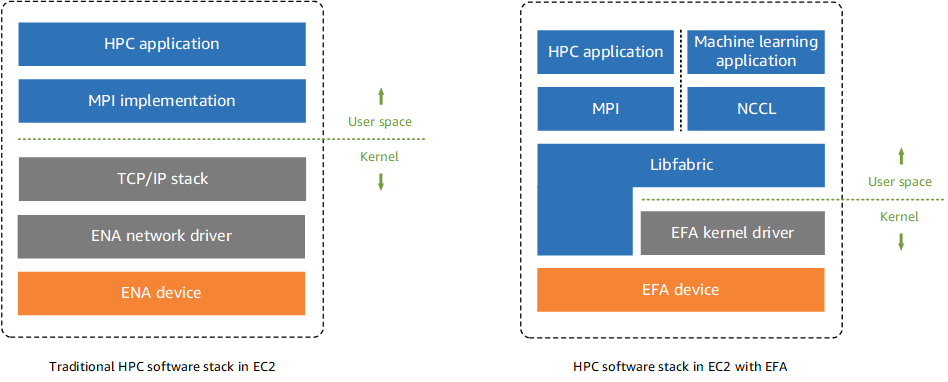
其核心优势源于 操作系统旁路 (OS-bypass) 机制。如下图所示,传统网络堆栈中,用户空间的应用(如 MPI, NCCL)需通过操作系统内核的 TCP/IP 协议栈与网络硬件通信。而 EFA 允许这些应用通过 Libfabric API 直接与 EFA 硬件设备通信,绕过了内核,从而显著减少了开销,提升了通信效率。
EFA 底层使用 可扩展可靠数据报 (Scalable Reliable Datagram, SRD) 协议,专为大规模云环境设计,提供可靠的、拥塞控制的传输。
1.4.2 EFA 的主要限制
在生产中使用 EFA 时,必须了解其关键限制:
- 网络范围: EFA 流量不可路由,且不能跨越可用区 (AZ) 或 VPC。所有需要进行 EFA 通信的实例必须位于同一个子网内,并属于同一个安全组。
- 实例兼容性: 特定实例类型之间(如 P4d/P4de/DL1 与其他类型)的 EFA 流量不受支持。
- 安全组: EFA 绕过内核,因此安全组规则的评估也发生在硬件层面。您必须配置一个安全组,允许其内部所有实例之间相互收发所有流量。
- 支持的接口: EFA 支持 Open MPI, Intel MPI, NCCL 等主流库。
- 成本: 在受支持的实例上启用 EFA 无需额外费用。
1.4.3 NVIDIA GPUDirect RDMA
在 P4d 等实例上,EFA 支持 GPUDirect RDMA (GDR)。该技术允许网络接口卡(NIC)直接读写远程 GPU 内存,实现了跨节点 GPU 之间的直接通信,进一步降低了通信延迟并减轻了 CPU 的负担。
1.4.4 AWS-OFI-NCCL 插件
NVIDIA 的 NCCL 是实现 GPU 间集体通信算法(如 All-Reduce)的标准库。AWS 开发的 AWS OFI NCCL 插件 将 NCCL 调用映射到 EFA 使用的 Libfabric 接口,从而使 NCCL 能够在 EFA 上高效运行。
1.5 应用场景
本指南中的最佳实践不仅适用于 LLM 训练,也广泛适用于任何类型的大模型训练,包括计算机视觉(CV)和多模态模型(如 Stable Diffusion)。典型的应用场景包括:
- 基础模型开发: 从零开始训练拥有数百亿甚至数千亿参数的通用语言模型。
- 模型微调: 在特定领域或任务的数据集上对现有的大型模型进行微调。
- 科学研究: 探索不同模型架构、优化器和训练数据对模型性能的影响。
2. 实际生产落地条件考虑
在生产环境中成功落地 LLM 训练项目,需要综合考虑计算资源、存储方案、任务编排、监控与容灾等多个方面。
2.1 计算资源与区域选择
- 实例选择:
ml.p4d.24xlarge是 LLM 训练常用的高性能实例。但最佳实践同样适用于其他 GPU 实例类型。 - 区域选择: 实例类型和所需的计算容量是选择 AWS 区域的关键因素。请参考 Amazon SageMaker 定价页面了解各区域支持的实例类型。建议与您的 AWS 客户团队联系,以确定最适合您工作负载的区域和容量。
- 配额提升: LLM 训练通常需要大规模、长时间运行的集群。因此,您很可能需要提升以下 SageMaker 服务配额:
- 单个训练任务的最长运行时间(
Longest run time for a training job) - 所有训练任务的总实例数(
Number of instances across all training jobs) - 单个训练任务的最大实例数(
Maximum number of instances per training job) - 特定实例类型(如
ml.p4d.24xlarge)的训练任务使用配额 - 训练任务温启动池(Warm Pool)的使用配额
- 单个训练任务的最长运行时间(
2.2 数据准备与加载
2.2.1 数据准备
LLM 的训练数据通常源自 Common Crawl、The Pile 等大规模自然文本语料库。数据准备阶段涉及数据清洗、去重、格式转换等步骤,这是一个可以高度并行的过程。SageMaker Training 和 SageMaker Processing 作业非常适合执行此类任务,它们支持 Dask, Ray, PySpark 等多种分布式计算框架。
2.2.2 数据存储与加载方案
根据数据集大小、访问模式和性能要求,可以选择以下几种存储和加载方案:
| 方案 | 优点 | 缺点/适用场景 |
|---|---|---|
| 本地 NVMe SSD | 性能最高,延迟最低。 | 容量有限(ml.p4d.24xlarge 为 8TB),每次任务启动时需要从 S3 复制数据。 |
| Amazon FSx for Lustre | 高性能并行文件系统,支持大规模数据集和低延迟随机访问。 | 需要额外管理 FSx 文件系统。适合需要高性能随机读写的场景。 |
| SageMaker Fast File Mode (FFM) | 以 POSIX 兼容接口呈现 S3 对象,按需流式读取,无需预先下载。 | 背后是 S3 API 调用,需控制并行读取的文件数量和顺序读取以避免 S3 节流。 |
| 自定义数据加载 | 灵活性最高,可重用现有代码,实现自定义错误处理和性能调优。 | 开发和维护成本较高。可使用 torchdata.datapipes, Webdataset, Boto3 等库。 |
2.2.3 与 Amazon S3 交互的最佳实践
Amazon S3 是训练数据和模型检查点(Checkpoint)的主要存储位置。为避免因请求频率过高而触发 503 Slow Down 错误,建议遵循以下实践:
- 使用多个 S3 前缀: 将训练数据和检查点分散到不同的 S3 存储桶或前缀(Prefix)中,以利用 S3 的水平扩展能力。
- 监控 S3 指标: 在 Amazon CloudWatch 中监控 S3 请求率,及时发现潜在瓶颈。
- 减少并发 S3 请求:
- 分层检查点: 先将检查点写入节点本地存储,再由一个进程统一上传到 S3,可将 PUT 请求数量减少 N 倍(N 为节点内的 GPU 数量)。
- 合并数据文件: 将多个训练样本打包到单个文件中,通过一次 S3 GET 请求读取多条记录,而不是每条记录都对应一次 GET 请求。
- 顺序读取: 如果使用 FFM,尽量顺序读取文件,并限制并行打开的文件数量。
2.3 分布式训练策略
SageMaker 提供了多种分布式训练方案,开发者可以根据团队技能和项目需求进行选择。
2.3.1 SageMaker 分布式库(推荐)
SageMaker 提供的专有库对 AWS 云环境进行了深度优化,性能和易用性更佳。
- SageMaker 分布式模型并行库 (SMP): 提供数据并行、流水线并行、张量并行、优化器状态分片、激活检查点和激活卸载等高级功能。该库曾成功用于在 920 个 NVIDIA A100 GPU 上训练 1750 亿参数的模型。
- SageMaker 分片数据并行库 (SMDDP): 该库实现了 MiCS 论文中提出的低通信开销模型并行策略,仅在数据并行组内进行模型参数分割,而不是在整个集群中。AWS 科学家曾使用该技术在 P4de 实例上以每 GPU 176 TFLOPS 的速度训练了一个 1.06 万亿参数的模型。
使用 SageMaker 分布式库的优势在于,开发者无需编写和维护自定义的并行进程启动器,启动逻辑已内置于 SageMaker SDK 中。
2.3.2 自管理方案
如果希望获得更大的灵活性或重用现有代码,可以选择自管理分布式训练。
- 使用 AWS 深度学习容器 (DLC): AWS 维护的 DLC 已预装并优化了主流深度学习框架(PyTorch, TensorFlow 等)及其依赖,并集成了 MPI,可以方便地启动并行代码。
- 构建自定义 Docker 镜像: 您可以从头开始或基于 DLC 扩展来构建自己的镜像。构建自定义镜像时,务必确保正确安装和配置了 EFA、NVIDIA NCCL 和 AWS-OFI-NCCL 插件,并设置了必要的环境变量。
2.4 任务编排
2.4.1 作业内编排
在 SageMaker 训练集群中,训练容器在每台机器上启动一次。您有三种方式来编排节点内的多个训练进程:
- 使用框架原生启动器: 将
torchrun或deepspeed等命令作为容器的入口点。 - 使用 SageMaker MPI 集成: 利用 DLC 中内置的 MPI 来启动多个训练进程。
- 使用 SageMaker 分布式库: 无需编写任何启动器代码,SDK 会自动处理。
2.4.2 作业间编排
LLM 项目涉及多次实验(参数搜索、规模测试、错误恢复等)。SageMaker Training 本身就是一个无服务器的 ML 作业编排器。
- 温启动池 (Warm Pools): 通过复用训练集群,可以显著减少连续作业之间的启动时间,加快迭代速度。
- SDK/CLI: 可以通过 Python (Boto3, SageMaker Python SDK) 或 AWS CLI 等多种方式以编程方式启动和管理训练作业。
2.5 监控与弹性
在大规模集群中,硬件故障是概率事件,必须有相应的监控和容灾机制。
2.5.1 监控
- 日志与指标: SageMaker 自动将训练脚本的
stdout/stderr日志以及 CPU/GPU/内存等系统资源利用率指标发送到 CloudWatch。 - 自定义指标: 可以通过正则表达式从日志中提取自定义训练指标(如 loss)并发送到 CloudWatch。
- SageMaker Profiler: 用于深入分析基础设施使用情况,并提供优化建议。
- 自动化事件响应: 结合 Amazon EventBridge 和 AWS Lambda,可以创建自动化逻辑来响应作业失败、成功等事件。
- SSH 访问: 使用社区维护的 SageMaker SSH Helper 库,可以在需要时登录到训练节点进行调试。
2.5.2 弹性与容灾
- 集群健康检查: 作业开始前,SageMaker 会对 GPU 实例进行健康检查,并自动替换有问题的实例。
- 内置重试与集群更新: 您可以配置 SageMaker 在遇到特定类型的内部服务器错误时自动重试作业。在重试期间,SageMaker 会替换掉出现不可恢复错误的实例,并重启健康的实例。
- 模型检查点 (Checkpointing): 定期保存模型训练状态至关重要。这是从故障中恢复并继续训练的基础。
2.5.3 检查点策略深度探讨
SageMaker 内置的检查点功能(将 /opt/ml/checkpoints 目录同步到 S3)虽然方便,但在大规模训练中可能遇到瓶颈(下载时间长、S3 流量大)。推荐以下高级策略:
- 写入 FSx for Lustre: 利用 FSx 的高性能 I/O,可以实现更灵活、更高效的分片检查点保存和加载方案。
- 自管理 S3 检查点: 自行编写代码,实现分片、非阻塞的检查点读写逻辑。例如,每个 rank 只保存和加载它所需要的那部分模型参数。
强烈建议每隔 1-3 小时对模型进行一次检查点操作,具体频率取决于开销和成本。
2.6 用户与权限管理
SageMaker 通过 AWS IAM 提供了精细的权限管理能力。
- 用户权限: 可以为用户或系统(Principal)授予启动训练资源的权限。
- 任务角色 (Execution Role): 每个训练任务都带有一个 IAM 角色,该角色定义了任务本身在运行时拥有的权限(例如,访问 S3 数据的权限)。
- SageMaker Role Manager: 这是一个简化工具,可以帮助您根据不同的用户角色(如数据科学家、MLOps 工程师)快速创建符合最小权限原则的 IAM 策略。
3. 参考资料与问答
3.1 常见问题与解答 (Q&A)
问:为什么我的 S3 访问速度慢或出现 503 错误? 答:这很可能是因为您超出了 S3 单个前缀的请求速率限制。请尝试以下优化措施:1) 将数据(训练集、检查点)分散到多个 S3 前缀或存储桶中;2) 减少并发请求,例如采用分层检查点策略;3) 将多个小文件合并成大文件。
问:如何确保我的分布式训练正确使用了 EFA 高性能网络?
答:在您的训练环境中设置环境变量 NCCL_DEBUG=INFO。在训练任务启动时,检查日志中是否包含 NCCL INFO NET/OFI Selected Provider is efa 和 NCCL INFO Using network AWS Libfabric 等信息。
问:训练一个大规模模型需要哪些 AWS 服务配额?
答:您至少需要关注并可能需要提升以下配额:单个训练任务的最长运行时间、账户下所有训练任务的总实例数、单个任务的最大实例数,以及您计划使用的特定 GPU 实例类型(如 ml.p4d.24xlarge)的vCPU数量配额。
问:大规模训练时,节点故障了怎么办? 答:首先,确保您的训练代码能够从检查点恢复。其次,配置 SageMaker 训练作业的自动重试策略。SageMaker 会在重试时自动替换掉故障节点。最后,在您的集合通信操作(collectives)中设置合理的超时时间,以便在节点无响应时能及时抛出错误,而不是无限期挂起。
3.2 相关参考文档
- 模型与科学
- SageMaker 功能与教程
- 底层技术
- 客户案例