基于 AWS 的生成式 AI 法律文档分析平台技术方案
基于 AWS 的生成式 AI 法律文档分析平台技术方案
1. 方案概述
本文档旨在详细阐述一个基于 AWS 云服务构建的生成式 AI 解决方案。该平台旨在实现对法律、合同等非结构化文档的自动化、智能化处理与分析。系统通过集成 Amazon Bedrock 的高级 AI 能力,结合强大的数据处理与编排服务,将原始文档转化为可供检索、分析和交互的结构化知识,最终通过 Web 应用为用户提供聊天驱动的智能问答、自助式报表生成等服务。
该方案的核心是构建一个从数据提取、向量化、存储、索引到上层应用交互的端到端自动化流程,确保系统的高效率、可扩展性和生产环境下的稳定性。
2. 核心组件与技术栈
| 服务组件 | 技术选型 | 核心职责 |
|---|---|---|
| 对象存储 | Amazon S3 | 存储原始法律文档、处理后的中间数据、以及部署所需的代码库。 |
| AI 服务 | Amazon Bedrock | 提供核心的生成式 AI 能力,主要用于 OCR 文本提取和未来的文本生成、摘要等。 |
| 向量数据库 | Amazon OpenSearch | 存储从文档中提取的文本向量 (Embeddings),提供高效的相似性搜索和检索引擎。 |
| 流程编排 | AWS Lambda / AWS Step Functions | [关键] 负责自动化执行整个数据处理管道,协调各个服务组件完成任务。 |
| 部署流水线 | AWS CodePipeline | 实现配置和应用代码的持续集成与持续部署 (CI/CD)。 |
| 用户交互 | Web UI | 提供用户与系统交互的前端界面,支持智能问答、报表编辑和图表生成。 |
3. 主要架构流程详解
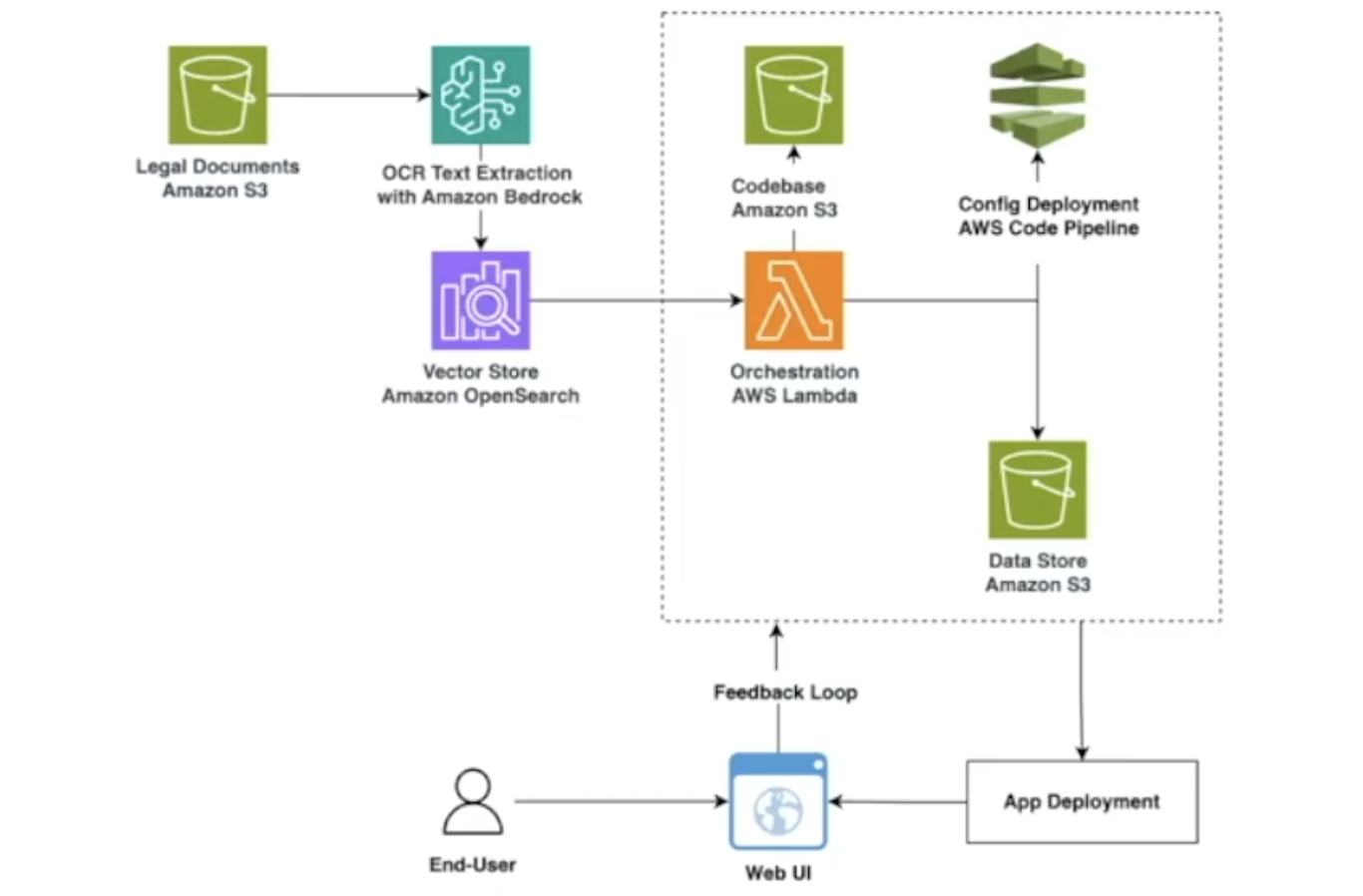
系统的数据流和处理逻辑遵循一个清晰的、事件驱动的模式,具体步骤如下:
- 文档上传: 用户或上游系统将原始法律文档(如 PDF、Word、图片格式)上传至指定的 Amazon S3 存储桶。
- 触发处理流程: S3 的文件上传事件自动触发流程编排引擎(Lambda 或 Step Functions),启动数据处理任务。
- 高精度文本提取: 编排引擎调用 Amazon Bedrock 的 OCR 功能,对文档进行深度内容识别,提取纯文本、表格、图像描述等信息。
- 文本向量化与存储: 提取出的文本块被送入向量化模型(可由 Bedrock 或 OpenSearch 内置模型提供),将文本转换为高维向量。
- 数据索引: 转换后的向量及对应的原始文本、元数据(如文档来源、页码等)被一同存储到 Amazon OpenSearch Service 中,并建立索引,以便快速检索。
- 用户查询与交互:
- 终端用户通过 Web UI 发起查询(例如:“查询合同中关于违约责任的条款”)。
- 应用后端接收到查询后,将其同样转换为向量。
- 系统使用该查询向量在 OpenSearch 中执行 Top-K 相似性搜索,检索出最相关的原始文本片段。
- 将检索到的文本片段作为上下文,连同用户原始问题,一起提交给 Bedrock 的大语言模型。
- Bedrock 生成精准、自然的回答,返回给用户。
- 反馈与优化: 系统记录用户的交互和反馈,用于未来对模型或检索逻辑的持续优化。
4. 生产环境挑战与优化策略:Lambda vs. Step Functions
在原型或简单场景中,使用单个 AWS Lambda 函数编排整个流程是可行的。但在生产环境中,随着业务复杂度的增加,这种方式会带来一系列挑战。
4.1. 单独使用 Lambda 面临的挑战
执行超时限制 (Timeout Limit)
- 挑战: AWS Lambda 的最大执行时间为 15 分钟。对于大型文档的处理、复杂的计算或等待外部 API 响应等长耗时任务,极易触发超时导致整个流程失败。
- 后果: 任务处理中断,数据不一致,需要复杂的外部逻辑来进行重试或状态恢复。
复杂的状态管理 (State Management)
- 挑战: Lambda 是无状态的。如果编排流程包含多个步骤(如提取 -> 转换 -> 验证 -> 存储),需要在两次 Lambda 调用之间传递状态,开发者必须自行实现状态管理机制(例如,使用 DynamoDB 或 S3 文件),这会增加大量“胶水代码”,使逻辑变得脆弱且难以维护。
错误处理与重试逻辑复杂
- 挑战: 生产级的流程必须具备健壮的错误处理和重试能力。在 Lambda 代码中手动实现针对不同下游服务(如 OpenSearch、Bedrock)的、带指数退避的重试逻辑,代码会非常臃肿且容易出错。
可观测性与调试困难 (Observability & Debugging)
- 挑战: 当流程失败时,通过 CloudWatch Logs 在一长串日志中定位根本原因非常耗时。追踪一个业务请求在多个服务、多个 Lambda 之间的调用链也极为困难。
4.2. 优化方案:采用 AWS Step Functions 进行编排
为了解决上述挑战,我们强烈建议在生产环境中使用 AWS Step Functions 替代单一的 Lambda 函数来负责核心流程编排。Step Functions 是一个专为构建分布式应用和微服务工作流而设计的服务。
优化后的架构思路:将原先庞大的 Lambda 函数拆分为多个职责单一的小函数(例如 extractText, convertToVector, storeInOpenSearch),然后使用 Step Functions 以状态机的方式来定义和执行它们之间的调用逻辑。
4.3. Step Functions 带来的核心优势
完美解决超时问题: Step Functions 的工作流可以运行长达一年。它通过调用短时运行的 Lambda 函数来完成每个步骤,从根本上规避了 15 分钟的限制。
内置状态管理: Step Functions 会自动持久化每一步的输入和输出,并将其传递给下一步。开发者无需编写任何状态管理代码,极大地简化了逻辑。
强大的错误处理与重试能力:
- 可以在状态机的定义中,为每一步配置精细化的
Retry和Catch策略。 - 示例: “如果调用 OpenSearch 失败,则每 10 秒重试一次,最多重试 3 次,退避因子为 2.0。如果最终仍然失败,则执行一个告警 Lambda 并将任务移至死信队列。” 这一切都通过声明式 JSON/YAML 配置实现,无需在 Lambda 中编写代码。
- 可以在状态机的定义中,为每一步配置精细化的
卓越的可观测性:
- Step Functions 提供可视化工作流界面,可以实时查看每个执行实例的流程图,哪一步成功、哪一步失败、每一步的输入输出是什么,一目了然。
- 与 AWS X-Ray 集成后,可以获得端到端的调用链追踪,快速定位性能瓶颈和故障点。
逻辑与代码解耦: 业务流程(“先做什么,后做什么”)在 Step Functions 的状态机中定义,而具体的业务实现则封装在 Lambda 函数中。这种分离使得两部分都可以独立修改、测试和维护,系统扩展性更强。
4.4. 高并发上传场景的架构演进:引入 EventBridge 与 SQS
当系统面临海量文档同时上传的极端高并发场景时,S3 事件直接触发 Step Functions 的方式可能会对下游服务(尤其是数据库和需要较长处理时间的 AI 模型服务)造成巨大冲击,即所谓的“惊群效应”(Thundering Herd)。为了进一步提升系统的弹性和鲁棒性,我们可以引入 Amazon EventBridge 和 Amazon SQS 对架构进行解耦和缓冲。
演进后的架构流程:
- 事件捕获: S3 将文件上传事件(
s3:ObjectCreated:*)发送到 Amazon EventBridge。 - 事件路由与缓冲: EventBridge 根据预设规则,将匹配的事件路由到 Amazon SQS 队列中。SQS 队列在此处扮演了关键的缓冲区角色。
- 消费与处理: Step Functions 工作流的触发器从直接监听 S3 事件,变更为从 SQS 队列中拉取消息。通过配置 SQS 触发器的
BatchSize和 Lambda 的预留并发,我们可以精确地控制消费速率,实现“削峰填谷”,从而保护下游服务。
引入 EventBridge 和 SQS 带来的优势:
- 削峰填谷与系统保护: SQS 队列能够平滑处理突发流量,将瞬时的高并发请求转化为平稳的、可控的消费流,有效防止下游服务因过载而崩溃。
- 提升系统韧性: 如果 Step Functions 工作流或其调用的某个服务暂时失败,消息会保留在 SQS 队列中,并在可见性超时后被自动重试。配合配置死信队列(DLQ),可以确保关键任务不丢失,并为问题排查提供依据。
- 完全解耦与未来扩展: EventBridge 作为一个中心化的事件总线,允许未来轻松地为“文档上传”这一事件增加新的订阅者。例如,可以增加一个独立的审计服务来记录所有上传操作,而无需对现有上传逻辑做任何修改,架构的扩展性大大增强。
4.5. 响应质量优化:引入 Bedrock 模型评估
为确保RAG系统输出的质量和可靠性,必须建立一套客观、可重复的评估体系。Amazon Bedrock 模型评估功能为此提供了标准化的解决方案,其核心是采用 LLM-as-a-Judge(以大模型为裁判)机制,对RAG流程的输出进行自动化评分。
评估流程与核心指标:
该功能通过对照“黄金数据集”(包含问题、上下文、标准答案),从多个维度对模型生成内容进行量化评估。针对法律等要求严谨的RAG场景,关键评估指标包括:
- 忠实度 (Faithfulness): 确保答案严格基于检索到的上下文,有效抑制内容捏造(幻觉)。
- 相关性 (Relevancy): 确保答案与用户问题高度相关。
- 引用精确度 (Citation Precision): 验证答案中的引用信息,确保其准确指向原始上下文出处。
- 引用覆盖率 (Citation Coverage): 确保答案中来自上下文的关键信息均被正确引用。
集成价值与 MLOps 实践:
- 数据驱动迭代: 为 RAG 系统各组件(如 Embedding 模型、Prompt、重排序器)的优化提供量化依据,实现科学的 A/B 测试。
- 自动化回归测试: 可集成于 CI/CD 流水线,在模型或代码变更后自动运行评估作业,防止系统性能下降,确保生产环境的稳定性。
- 构建 MLOps 闭环: 实现了从“开发”到“评估”再到“优化”的完整 MLOps 流程,驱动 RAG 系统持续演进。
5. 部署与运维
本方案采用 AWS CodePipeline 实现 CI/CD 自动化。
- 源代码管理: 应用代码、Lambda 函数代码、Step Functions 状态机定义等均存储在 Git 仓库中(如 AWS CodeCommit 或 GitHub)。
- 构建与部署: 当代码变更推送到主分支时,CodePipeline 会自动触发,执行构建、测试,并使用 AWS CloudFormation 或 SAM 将相关的 Lambda、Step Functions 和 API Gateway 等资源部署到目标环境。
- 监控与告警: 使用 Amazon CloudWatch 对 Lambda 的执行次数/错误率、Step Functions 的失败率以及 OpenSearch 的集群健康状况进行全面监控,并配置告警。
6. 总结
本方案详细介绍了一个功能强大且技术先进的生成式 AI 文档分析平台。通过采用 AWS Step Functions 作为核心编排引擎,我们不仅能够实现复杂的业务流程,更能确保系统在生产环境下的健壮性、可扩展性和可维护性,有效规避了单独使用 Lambda 进行复杂编排所带来的潜在风险。
7. 参考资料
- Evaluate models or RAG systems using Amazon Bedrock Evaluations (Now Generally Available)
- Amazon S3 Documentation
- Amazon Bedrock Documentation
- Amazon OpenSearch Service Documentation
- AWS Lambda Documentation
- AWS Step Functions Documentation
- AWS CodePipeline Documentation
- Amazon EventBridge Documentation
- Amazon SQS Documentation
- Cross River Bank Automated Deal Monitoring Pipeline with AWS GenAI Services | AWS Events