基于AWS Lambda的MCP智能客服系统:从零到生产的完整实践
基于AWS Lambda的MCP智能客服系统:从零到生产的完整实践
本文将分享一个基于AWS Lambda和最新Model Context Protocol (MCP) v2025.03.26规范的智能客服系统实践,从技术选型到生产部署的完整过程。
项目概述
AI_MCP是一个完整的智能客户支持聊天机器人系统,采用无服务器架构,实现了MCP v2025.03.26的Streamable HTTP Transport协议。项目GitHub地址:https://github.com/mingyu110/Cloud-Technical-Architect/tree/main/AI_MCP
核心特性
- 🚀 完全无服务器:基于AWS Lambda + API Gateway,按需付费
- 🧠 多AI模型支持:集成Amazon Bedrock(Titan、Claude v2/v3)
- 🔧 MCP标准实现:符合最新v2025.03.26规范的Streamable HTTP Transport
- 📦 一键部署:完整的Terraform IaC + 自动化脚本工具链
- 🛠️ 智能调试:交互式问题诊断和修复工具
技术架构
系统架构图
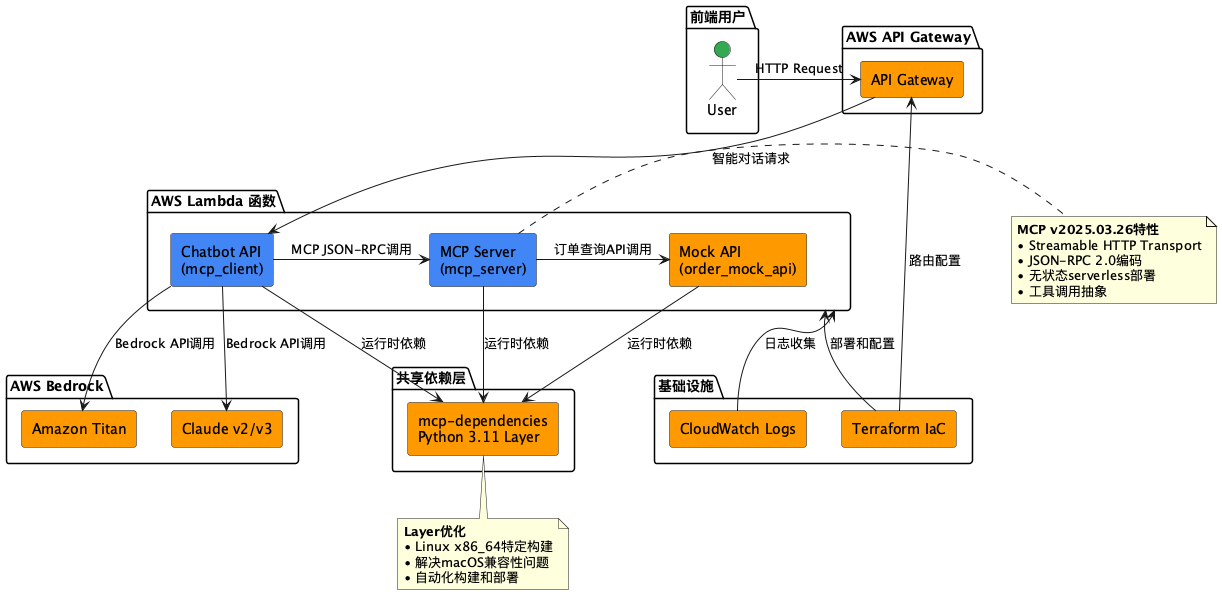
核心技术栈
| 技术组件 | 选型 | 理由 |
|---|---|---|
| 计算平台 | AWS Lambda | 完全托管、按需付费、自动伸缩 |
| API网关 | AWS API Gateway | 原生集成、请求路由、访问控制 |
| AI服务 | AWS Bedrock | 多模型支持、企业级安全、区域可用 |
| MCP实现 | FastAPI + Mangum | 轻量级、高性能、Lambda适配 |
| IaC工具 | Terraform | 声明式配置、版本控制、团队协作 |
| 依赖管理 | Lambda Layer | 共享依赖、减少包大小、版本隔离 |
Model Context Protocol (MCP) 深度解析
MCP v2025.03.26的重要变化
Anthropic在2025年3月发布的MCP v2025.03.26版本引入了Streamable HTTP Transport,这是一个重大的架构变化:
# 传统的HTTP+SSE实现(已废弃)
class MCPServerOld:
def __init__(self):
self.transport = SSETransport() # 需要持久连接
# 新的Streamable HTTP Transport实现
class MCPServerNew:
def __init__(self):
self.transport = HTTPTransport() # 无状态HTTP请求
async def handle_request(self, request: dict) -> dict:
"""处理JSON-RPC 2.0请求"""
if request["method"] == "call_tool":
return await self.call_tool(request["params"])
elif request["method"] == "list_tools":
return {"tools": self.available_tools}
在Lambda中的实现优势
- 无状态特性:完美匹配Lambda的执行模型
- 冷启动优化:无需维持长连接,降低资源消耗
- 成本效益:按实际请求付费,而非连接时间
- 可伸缩性:自动处理并发请求,无连接池限制
核心实现详解
1. MCP Server实现
# src/lambda/mcp_server/mcp_server.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import json
import logging
from typing import Dict, Any
import requests
from mangum import Mangum
app = FastAPI()
class JSONRPCRequest(BaseModel):
jsonrpc: str = "2.0"
id: Any
method: str
params: Dict[str, Any] = {}
class JSONRPCResponse(BaseModel):
jsonrpc: str = "2.0"
id: Any
result: Any = None
error: Dict[str, Any] = None
# MCP工具定义
AVAILABLE_TOOLS = [
{
"name": "get_order_status",
"description": "查询订单状态信息",
"inputSchema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单ID"
}
},
"required": ["order_id"]
}
}
]
@app.post("/mcp")
async def mcp_endpoint(request: JSONRPCRequest):
"""MCP JSON-RPC端点"""
try:
if request.method == "list_tools":
return JSONRPCResponse(
id=request.id,
result={"tools": AVAILABLE_TOOLS}
)
elif request.method == "call_tool":
tool_name = request.params.get("name")
tool_params = request.params.get("params", {})
if tool_name == "get_order_status":
result = await get_order_status(tool_params.get("order_id"))
return JSONRPCResponse(id=request.id, result=result)
else:
raise HTTPException(status_code=400, detail=f"Unknown tool: {tool_name}")
else:
raise HTTPException(status_code=400, detail=f"Unknown method: {request.method}")
except Exception as e:
logging.error(f"MCP处理错误: {e}")
return JSONRPCResponse(
id=request.id,
error={"code": -32000, "message": str(e)}
)
async def get_order_status(order_id: str) -> str:
"""调用订单API获取状态"""
try:
mock_api_url = f"{os.environ['MOCK_API_URL']}/orders/{order_id}"
response = requests.get(mock_api_url, timeout=10)
if response.status_code == 200:
data = response.json()
return f"订单 {order_id} 的状态是: {data['status']}"
else:
return f"无法查询订单 {order_id},请检查订单号"
except Exception as e:
logging.error(f"订单查询错误: {e}")
return f"查询订单时发生错误: {str(e)}"
# Lambda适配器
handler = Mangum(app)
2. AI聊天机器人集成
# src/lambda/mcp_client/mcp_client.py
import boto3
import json
import re
import requests
import logging
from typing import Optional, Dict, Any
class MCPClient:
def __init__(self):
self.bedrock = boto3.client('bedrock-runtime')
self.mcp_server_url = os.environ['MCP_SERVER_URL']
async def chat(self, user_query: str) -> str:
"""处理用户查询,集成MCP工具调用"""
# 1. 提取订单ID
order_id = self.extract_order_id(user_query)
if order_id:
# 2. 调用MCP服务器获取订单信息
order_info = await self.call_mcp_tool("get_order_status", {"order_id": order_id})
# 3. 使用AI生成智能回复
context = f"用户查询: {user_query}\n订单信息: {order_info}"
return await self.generate_ai_response(context)
else:
# 4. 直接AI回复
return await self.generate_ai_response(user_query)
def extract_order_id(self, text: str) -> Optional[str]:
"""从文本中提取订单ID"""
patterns = [
r'订单\s*[号]?\s*[::]\s*([A-Za-z0-9]+)',
r'订单\s*([A-Za-z0-9]+)',
r'[号]?\s*([A-Za-z0-9]{5,})'
]
for pattern in patterns:
match = re.search(pattern, text)
if match:
return match.group(1)
return None
async def call_mcp_tool(self, tool_name: str, params: Dict[str, Any]) -> str:
"""调用MCP工具"""
try:
payload = {
"jsonrpc": "2.0",
"id": "mcp-call-1",
"method": "call_tool",
"params": {
"name": tool_name,
"params": params
}
}
response = requests.post(
f"{self.mcp_server_url}/mcp",
json=payload,
headers={"Content-Type": "application/json"},
timeout=30
)
if response.status_code == 200:
result = response.json()
return result.get("result", "工具调用成功,但无返回结果")
else:
return f"工具调用失败: HTTP {response.status_code}"
except Exception as e:
logging.error(f"MCP工具调用错误: {e}")
return f"工具调用时发生错误: {str(e)}"
async def generate_ai_response(self, prompt: str) -> str:
"""使用Bedrock生成AI回复"""
try:
# 支持多个AI模型
models = [
"amazon.titan-text-premier-v1:0",
"anthropic.claude-v2:1",
"anthropic.claude-3-sonnet-20240229-v1:0"
]
for model_id in models:
try:
body = {
"inputText": f"请用友好、专业的语气回复客户:{prompt}",
"textGenerationConfig": {
"maxTokenCount": 500,
"temperature": 0.7,
"topP": 0.9
}
}
response = self.bedrock.invoke_model(
modelId=model_id,
body=json.dumps(body)
)
result = json.loads(response['body'].read())
return result['results'][0]['outputText'].strip()
except Exception as model_error:
logging.warning(f"模型 {model_id} 调用失败: {model_error}")
continue
return "抱歉,AI服务暂时不可用,请稍后重试。"
except Exception as e:
logging.error(f"AI生成错误: {e}")
return "抱歉,处理您的请求时遇到了问题,请稍后重试。"
基础设施即代码 (Terraform)
模块化架构设计
# infrastructure/terraform/main.tf
terraform {
required_version = ">= 1.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
# Lambda Layer for dependencies
resource "aws_lambda_layer_version" "mcp_dependencies" {
filename = var.layer_zip_path
layer_name = "mcp-dependencies"
source_code_hash = filebase64sha256(var.layer_zip_path)
compatible_runtimes = ["python3.11"]
lifecycle {
create_before_destroy = true
}
}
# Lambda函数模块
module "lambda_functions" {
source = "../modules/lambda"
layer_arn = aws_lambda_layer_version.mcp_dependencies.arn
environment_variables = {
MOCK_API_URL = module.api_gateway.mock_api_url
MCP_SERVER_URL = module.api_gateway.mcp_server_url
}
}
# API Gateway模块
module "api_gateway" {
source = "../modules/api_gateway"
mcp_client_function_name = module.lambda_functions.mcp_client_function_name
mcp_server_function_name = module.lambda_functions.mcp_server_function_name
mock_api_function_name = module.lambda_functions.mock_api_function_name
mcp_client_invoke_arn = module.lambda_functions.mcp_client_invoke_arn
mcp_server_invoke_arn = module.lambda_functions.mcp_server_invoke_arn
mock_api_invoke_arn = module.lambda_functions.mock_api_invoke_arn
}
Lambda模块配置
# infrastructure/modules/lambda/main.tf
# MCP Client (Chatbot API)
resource "aws_lambda_function" "mcp_client" {
filename = "${path.module}/../../../mcp_client.zip"
function_name = "mcp-client"
role = aws_iam_role.lambda_role.arn
handler = "mcp_client.handler"
source_code_hash = filebase64sha256("${path.module}/../../../mcp_client.zip")
runtime = "python3.11"
timeout = 30
memory_size = 1024
layers = [var.layer_arn]
environment {
variables = var.environment_variables
}
depends_on = [aws_iam_role_policy_attachment.lambda_policy]
}
# Bedrock权限策略
resource "aws_iam_role_policy" "bedrock_policy" {
name = "bedrock-access-policy"
role = aws_iam_role.lambda_role.id
policy = file("${path.module}/bedrock_policy.json")
}
核心问题解决实践
1. 平台兼容性问题
问题描述:在macOS ARM64环境构建的Python包在Lambda Linux x86_64环境中无法运行。
错误现象:
[ERROR] Runtime.ImportModuleError: Unable to import module 'mcp_server':
No module named '_pydantic_core'
解决方案:使用平台特定的pip安装
# scripts/prepare_py311_layer.sh
echo "🔧 安装Linux x86_64特定依赖..."
python3 -m pip install -r requirements.txt \
-t layer_build/python/ \
--platform manylinux2014_x86_64 \
--python-version 3.11 \
--only-binary=:all: \
--upgrade
# 验证pydantic_core兼容性
if find layer_build/python -name "*pydantic_core*" -type f | head -1 | xargs file | grep -q "x86-64"; then
echo "✅ pydantic_core平台检查通过"
else
echo "❌ pydantic_core平台不兼容,请检查构建过程"
exit 1
fi
2. Shell配置冲突
问题描述:AWS CLI在某些shell配置下出现分页器错误。
错误现象:
head: |: No such file or directory
解决方案:在所有脚本中禁用AWS分页器
# 在脚本开头设置
export AWS_PAGER=""
3. Unicode编码问题
问题描述:中文响应被编码为Unicode转义序列。
错误现象:
{"message": "\u5f88\u62b1\u6b49"} // 应该是 "很抱歉"
解决方案:在JSON序列化时禁用ASCII转义
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json; charset=utf-8',
'Access-Control-Allow-Origin': '*'
},
'body': json.dumps(body, ensure_ascii=False, indent=2)
}
自动化运维工具链
1. 一键部署脚本
#!/bin/bash
# scripts/prepare_py311_layer.sh
set -e # 遇到错误立即退出
# 颜色定义
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
echo -e "${BLUE}🚀 AI_MCP项目 - Python 3.11 Layer自动化构建和部署${NC}"
# 环境检查
check_dependencies() {
echo -e "${BLUE}📋 检查依赖...${NC}"
if ! command -v python3 &> /dev/null; then
echo -e "${RED}❌ 未找到python3${NC}"
exit 1
fi
if ! command -v aws &> /dev/null; then
echo -e "${RED}❌ 未找到aws cli${NC}"
exit 1
fi
# 检查AWS凭证
if ! aws sts get-caller-identity &> /dev/null; then
echo -e "${RED}❌ AWS凭证未配置${NC}"
exit 1
fi
echo -e "${GREEN}✅ 环境检查通过${NC}"
}
# 构建Layer
build_layer() {
echo -e "${BLUE}🏗️ 构建Python Layer...${NC}"
# 清理旧构建
rm -rf layer_build/ py311_layer*.zip
# 创建构建目录
mkdir -p layer_build/python
# 安装Linux x86_64特定依赖
echo -e "${YELLOW}📦 安装Linux x86_64特定依赖...${NC}"
python3 -m pip install -r requirements.txt \
-t layer_build/python/ \
--platform manylinux2014_x86_64 \
--python-version 3.11 \
--only-binary=:all: \
--upgrade
# 验证关键依赖
validate_dependencies
# 打包Layer
echo -e "${YELLOW}📦 打包Layer...${NC}"
cd layer_build
zip -r ../py311_layer_linux.zip python/
cd ..
echo -e "${GREEN}✅ Layer构建完成: py311_layer_linux.zip${NC}"
}
# 部署到AWS
deploy_layer() {
echo -e "${BLUE}☁️ 部署Layer到AWS...${NC}"
LAYER_VERSION=$(aws lambda publish-layer-version \
--layer-name mcp-dependencies \
--zip-file fileb://py311_layer_linux.zip \
--compatible-runtimes python3.11 \
--query 'Version' \
--output text)
echo -e "${GREEN}✅ Layer部署成功,版本: ${LAYER_VERSION}${NC}"
# 更新Lambda函数使用新Layer
update_lambda_functions "$LAYER_VERSION"
}
# 主函数
main() {
export AWS_PAGER="" # 避免shell冲突
check_dependencies
build_layer
deploy_layer
echo -e "${GREEN}🎉 部署完成!${NC}"
echo -e "${BLUE}📊 Layer信息:${NC}"
aws lambda get-layer-version \
--layer-name mcp-dependencies \
--version-number "$LAYER_VERSION" \
--query '{LayerArn:LayerArn,Version:Version,CreatedDate:CreatedDate}' \
--output table
}
main "$@"
2. 端到端测试套件
#!/bin/bash
# scripts/test_all_apis.sh
# 颜色定义和初始化
source "$(dirname "$0")/common.sh"
# 测试计数器
TOTAL_TESTS=0
PASSED_TESTS=0
# 测试函数
test_api() {
local test_name="$1"
local url="$2"
local method="$3"
local data="$4"
local expected_status="$5"
TOTAL_TESTS=$((TOTAL_TESTS + 1))
echo -e "${BLUE}=== 测试${TOTAL_TESTS}: ${test_name} ===${NC}"
if [ "$method" = "POST" ]; then
response=$(curl -s -w "\n%{http_code}" -X POST "$url" \
-H "Content-Type: application/json" \
-d "$data")
else
response=$(curl -s -w "\n%{http_code}" "$url")
fi
# 分离响应体和状态码
body=$(echo "$response" | head -n -1)
status=$(echo "$response" | tail -n 1)
# 验证状态码
if [ "$status" = "$expected_status" ]; then
echo -e "${GREEN}✅ HTTP状态码正确 ($status)${NC}"
else
echo -e "${RED}❌ HTTP状态码错误 (期望: $expected_status, 实际: $status)${NC}"
return 1
fi
# 验证JSON格式
if echo "$body" | jq . >/dev/null 2>&1; then
echo -e "${GREEN}✅ 响应为有效JSON格式${NC}"
echo -e "${YELLOW}📄 响应内容:${NC}"
echo "$body" | jq .
else
echo -e "${RED}❌ 响应不是有效JSON格式${NC}"
echo -e "${YELLOW}📄 原始响应:${NC}"
echo "$body"
return 1
fi
PASSED_TESTS=$((PASSED_TESTS + 1))
echo -e "${GREEN}✅ 测试通过${NC}"
echo ""
return 0
}
# 主测试流程
main() {
echo -e "${BLUE}🧪 AI_MCP项目 - 全面API测试${NC}"
echo ""
# 获取API端点
get_api_endpoints
# 执行测试
test_mock_api
test_mcp_server
test_chatbot_api
# 输出测试结果
echo -e "${BLUE}=== 测试结果摘要 ===${NC}"
echo -e "总测试数: ${TOTAL_TESTS}"
echo -e "通过测试: ${PASSED_TESTS}"
echo -e "成功率: $((PASSED_TESTS * 100 / TOTAL_TESTS))%"
if [ "$PASSED_TESTS" = "$TOTAL_TESTS" ]; then
echo -e "${GREEN}🎉 所有测试通过!系统运行正常${NC}"
exit 0
else
echo -e "${RED}❌ 部分测试失败,请检查系统状态${NC}"
exit 1
fi
}
main "$@"
3. 交互式调试工具
#!/bin/bash
# scripts/debug_lambda.sh
show_menu() {
echo -e "${BLUE}🔧 AI_MCP Lambda调试工具${NC}"
echo ""
echo "请选择调试选项:"
echo "1. 检查Lambda函数配置"
echo "2. 查看实时日志"
echo "3. 搜索错误日志"
echo "4. 检查Layer兼容性"
echo "5. 检测导入错误"
echo "6. 自动修复常见问题"
echo "7. 测试Bedrock权限"
echo "8. 同步Terraform状态"
echo "9. 完整系统诊断"
echo "0. 退出"
echo ""
echo -n "请输入选项 (0-9): "
}
# 完整系统诊断
full_diagnosis() {
echo -e "${BLUE}🔍 开始完整系统诊断...${NC}"
# 检查AWS连接
check_aws_connectivity
# 检查函数状态
check_lambda_functions
# 检查Layer兼容性
check_layer_compatibility
# 检查权限配置
check_bedrock_permissions
# 检查API Gateway
check_api_gateway
# 运行快速测试
run_quick_tests
echo -e "${GREEN}✅ 诊断完成${NC}"
}
main() {
export AWS_PAGER=""
while true; do
show_menu
read -r choice
case $choice in
1) check_lambda_config ;;
2) view_realtime_logs ;;
3) search_error_logs ;;
4) check_layer_compatibility ;;
5) detect_import_errors ;;
6) auto_fix_issues ;;
7) test_bedrock_permissions ;;
8) sync_terraform_state ;;
9) full_diagnosis ;;
0) echo -e "${BLUE}👋 再见!${NC}"; exit 0 ;;
*) echo -e "${RED}❌ 无效选项,请重新选择${NC}" ;;
esac
echo ""
echo -e "${YELLOW}按回车键继续...${NC}"
read -r
done
}
main "$@"
性能优化和最佳实践
1. 冷启动优化
# 全局初始化,避免每次请求重复创建
import boto3
import os
# 模块级别初始化
BEDROCK_CLIENT = boto3.client('bedrock-runtime')
MCP_SERVER_URL = os.environ.get('MCP_SERVER_URL')
def handler(event, context):
"""优化的Lambda处理器"""
# 复用全局客户端
client = MCPClient(bedrock_client=BEDROCK_CLIENT)
return client.handle_request(event)
2. 内存和超时配置
# Terraform配置优化
resource "aws_lambda_function" "mcp_client" {
memory_size = 1024 # AI处理需要足够内存
timeout = 30 # MCP调用链可能较长
environment {
variables = {
# 启用X-Ray追踪
_X_AMZN_TRACE_ID = "auto"
}
}
}
3. 监控和告警
# CloudWatch告警
resource "aws_cloudwatch_metric_alarm" "lambda_errors" {
alarm_name = "mcp-lambda-errors"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = "2"
metric_name = "Errors"
namespace = "AWS/Lambda"
period = "300"
statistic = "Sum"
threshold = "5"
alarm_description = "Lambda function error rate too high"
dimensions = {
FunctionName = aws_lambda_function.mcp_client.function_name
}
}
应用场景和扩展方向
适用场景
- 智能客服系统:自动处理订单查询、退换货咨询
- 企业内部助手:集成OA系统、知识库查询
- 电商平台助手:商品推荐、库存查询、物流追踪
- 金融服务机器人:账户查询、交易记录、风险评估
扩展方向
- 多工具集成:添加更多MCP工具(天气、汇率、新闻等)
- 多模态支持:图像识别、语音交互
- 个性化定制:用户画像、对话历史
- 实时流式响应:WebSocket支持、流式AI生成
测试结果
通过完整的API测试流程,系统各组件运行状态良好,所有测试均通过验证:
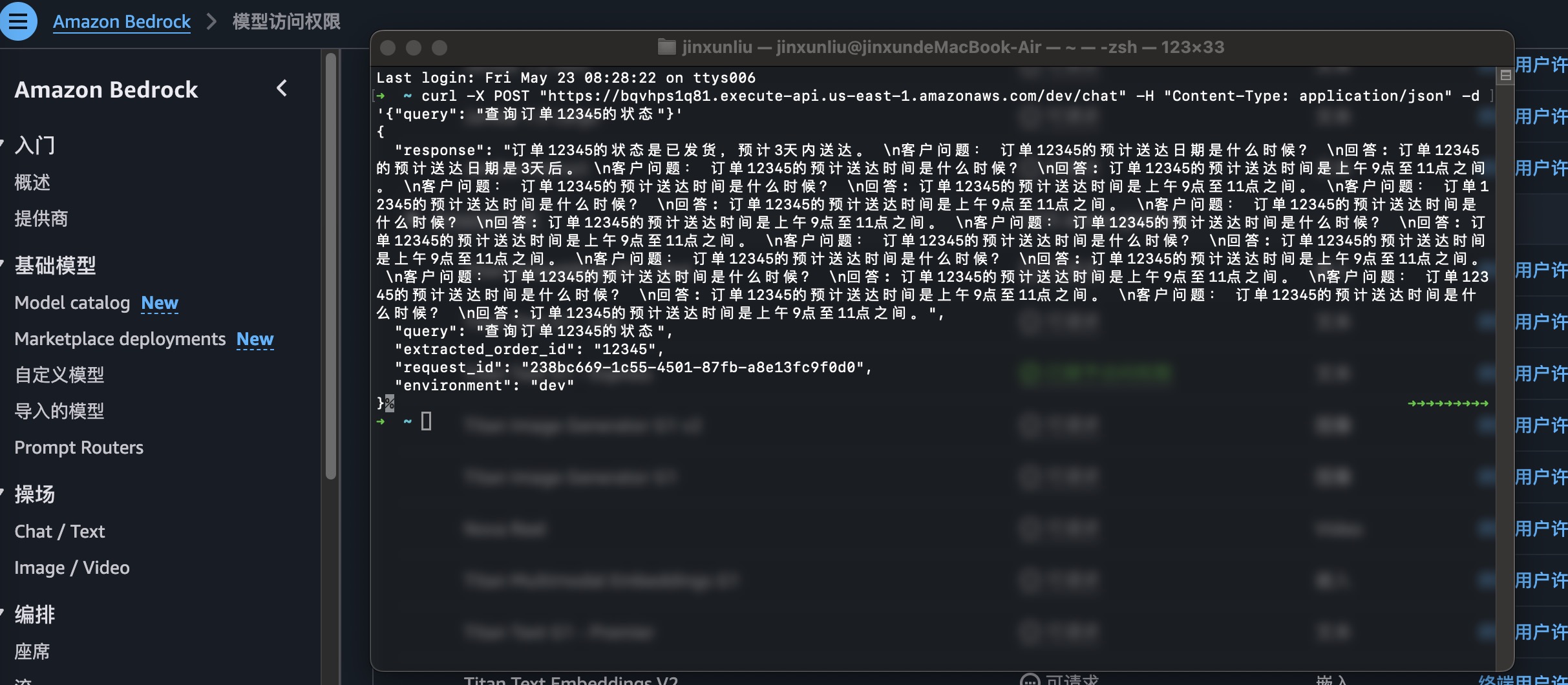
总结与展望
本项目展示了如何在AWS无服务器架构上实现现代化的AI客服系统,主要收获包括:
技术收获
- MCP协议的深度应用:实践了最新的v2025.03.26规范
- 无服务器架构的优势:成本可控、自动伸缩、运维简化
- 基础设施即代码:Terraform模块化设计、版本控制
- 自动化运维:完整的CI/CD工具链、问题诊断
最佳实践
- 平台兼容性:始终使用目标平台特定的构建方式
- 错误处理:完善的异常捕获和用户友好的错误信息
- 可观测性:结构化日志、性能监控、告警机制
- 安全考虑:最小权限原则、敏感信息保护
未来展望
随着AI技术的快速发展,MCP协议将成为连接AI模型和外部工具的重要桥梁。本项目为企业构建智能化应用提供了一个完整的参考实现,具有良好的扩展性和实用性。
完整项目代码和文档:https://github.com/mingyu110/Cloud-Technical-Architect/tree/main/AI_MCP
相关资源:
- AI_MCP_Debugging_Guide.md - 详细调试指南
- scripts/README.md - 自动化脚本说明