Kafka死信队列(DLQ)的生产实践与稳定性保障指南
Kafka死信队列(DLQ)的生产实践与稳定性保障指南
摘要
在基于Apache Kafka的事件驱动架构中,死信队列(Dead Letter Queue, DLQ)是处理消息失败的标准“安全网”。它通过隔离无法处理的消息,来保障主业务流程的连续性。然而,在真实的生产环境中,如果对DLQ的设计和监控不足,这个安全网本身也可能演变成导致整个系统雪崩的风险点。本文档通过分析一个由DLQ引发的真实生产事故,提炼出一套关于DLQ容量规划、动态策略调整、关键指标监控和架构设计的专业实践指南,并结合AWS云服务,提供具体的架构落地参考。
1. 背景:一个由DLQ引发的生产事故案例分析
1.1. 初始架构与“理想”逻辑
在一个典型的电子商务平台中,Kafka被广泛用于订单处理、库存更新、支付通知等核心业务流程。为了处理潜在的消息处理失败(如格式错误、下游服务瞬时故障等),我们设计了一套错误处理机制:
- 消费端逻辑:当一个消费者(Consumer)处理消息失败时,会进行最多3次的有限重试。
- DLQ机制:如果重试3次后依然失败,该消息将被发送到一个专门的DLQ Topic中。
- 后续处理:运维或开发人员在工作时间,对DLQ中的消息进行审查,根据失败原因决定是修复后重新投递(Reprocess),还是直接丢弃。
这个架构在数月内运行良好,成功捕获了所有预期的偶发性错误。
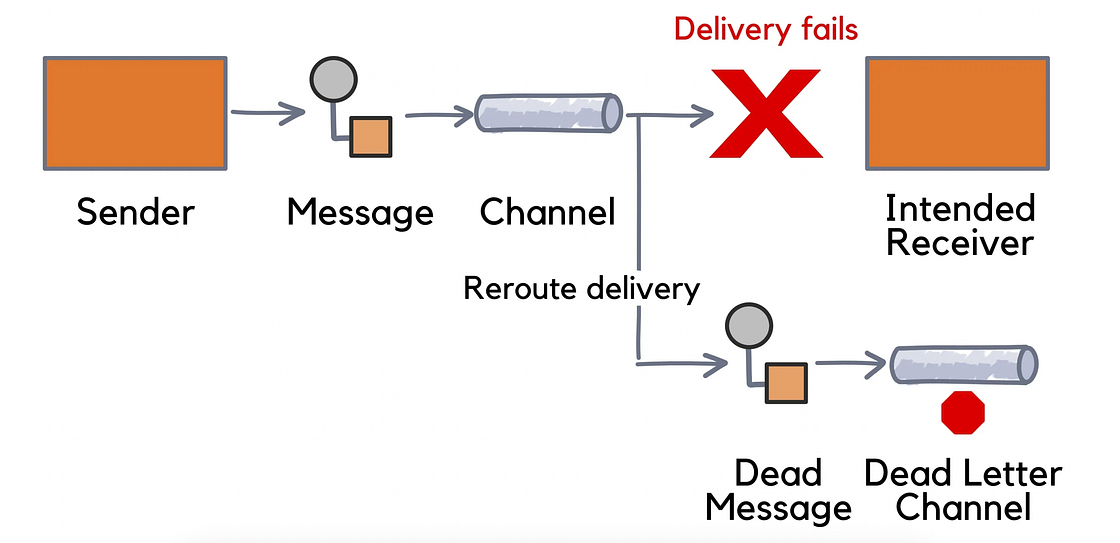
1.2. 事故触发与雪崩效应
触发点:一个上游供应商在未通知的情况下,突然更改了其API响应的数据格式。这导致我们的库存服务消费者在解析消息时100%失败。
雪崩效应:
- DLQ消息积压:该供应商在高峰期每小时发送约5万条库存更新。所有这些消息在重试3次后,全部涌入DLQ。在短短6小时内,DLQ中的消息从日常的几十条激增到超过30万条。
- 存储爆炸:为DLQ Topic设置的保留策略(Retention Policy)是7天。这些载荷颇大的库存消息(约300KB/条)导致DLQ占用的磁盘空间在短时间内急剧膨胀,很快达到了TB级别,触发了磁盘空间告警。
- 消费者延迟地狱:负责监控和处理DLQ的专用消费者,其设计容量远不能应对如此巨大的消息洪峰。其消费延迟(Lag)迅速飙升至数百万,导致整个监控系统告警泛滥。
- Broker内存压力:Kafka Broker为了缓冲不断涌入DLQ分区的数据,占用了大量内存,导致垃圾回收(GC)停顿时间显著增加,整个集群的性能急剧下降。
- 处理能力崩溃:不堪重负的DLQ消费者在反复尝试处理积压消息时,因资源耗尽而频繁崩溃重启,每一次重启都进一步加剧了系统的负载和混乱。
最终,这个本应是“安全网”的DLQ机制,成为了压垮整个Kafka集群的最后一根稻草。
2. 核心问题剖析:为何安全网会变成绊脚石?
这次事故暴露了在设计DLQ策略时,那些文档中很少提及的、隐藏的陷阱。
- 容量规划不足:我们为DLQ规划的容量和处理能力,是基于“正常”的、低于0.1%的错误率来估算的,而完全没有考虑到上游或自身系统发生**100%“中毒”**的灾难性场景。DLQ本身也需要进行容量规划。
- 监控盲区:我们对核心业务Topic的监控细致入微,但却将DLQ的监控视为次要任务。DLQ的消息增长率和消费者延迟,实际上是反映系统健康状况的“金丝雀”,是更需要被关注的关键告警指标。
- 静态保留策略的风险:7天的保留策略在常规运营下是合理的,但在危机中,它成了一个加速存储耗尽的“定时炸弹”。
- 缺乏熔断机制:当错误处理机制本身面临巨大压力时,我们没有任何自动化的“熔断”措施来保护它。整个系统只能被动地承受所有失败消息的冲击,直到崩溃。
3. 生产系统稳定性保障策略
基于上述教训,我们必须建立一套更具弹性的、立体的DLQ稳定性保障体系。
3.1. 动态保留策略:根据DLQ大小调整
静态的保留策略缺乏弹性。我们应建立一套自动化机制,根据DLQ的健康状况动态调整其保留策略。
实现思路: 创建一个定时的巡检任务(如每5分钟执行一次的CronJob),该任务执行以下逻辑:
- 使用Kafka命令行工具(如
kafka-run-class.sh kafka.tools.GetOffsetShell)或Admin API,获取DLQ Topic当前的总消息数或磁盘占用大小。 - 将获取的值与预设的“危险”阈值进行比较。
- 如果超过阈值,立即通过
kafka-configs.sh命令,将该DLQ Topic的retention.ms参数修改为一个极短的值(如1小时:3600000),以快速释放磁盘空间,避免存储被打满。 - 如果低于阈值,则将其恢复到常规的保留时长(如7天:
604800000)。
3.2. 关键生产监控指标
必须将DLQ的监控提升到与核心业务同等的优先级。以下是必须监控的关键指标:
- DLQ消息瞬时增长率
- DLQ消费者组延迟 (Consumer Group Lag)
- DLQ主题磁盘占用
- Kafka Broker核心指标(GC暂停时间、JVM内存、网络IO等)
3.3. 纵深防御:构建弹性的DLQ架构
单一的DLQ无法应对所有场景,需要构建一个更有弹性的、分层的错误处理架构。
- 分层DLQ策略 (Tiered DLQ Strategy)
- 生产者侧熔断机制 (Producer-side Circuit Breaker)
- DLQ消费者自动伸缩 (Auto-scaling DLQ Consumers)
4. 云上实现:AWS环境下的DLQ稳定性架构落地
将上述理论策略与AWS云服务相结合,可以构建一个高度自动化和弹性的DLQ防护体系。本章节以在AWS上使用Amazon MSK (Managed Streaming for Kafka) 为例。
4.1. AWS上的DLQ载体选型
在AWS上,除了使用另一个Kafka Topic作为DLQ,我们有更灵活、更云原生的选择:
Amazon SQS (Simple Queue Service):这是最推荐的DLQ载体。消费者在最终失败后,不将消息发往Kafka DLQ Topic,而是直接发送到SQS队列。
- 优势:
- 完全解耦:将死信的处理压力从MSK集群中彻底剥离,避免影响核心业务。
- 与Lambda完美集成:可以配置一个Lambda函数直接由SQS队列触发,轻松实现对死信的自动化分析、告警或重新处理,并且Lambda可以根据队列深度自动扩缩容。
- 自带DLQ:SQS本身也支持配置DLQ,为死信处理逻辑提供第二层保障。
- 优势:
Amazon S3 (Simple Storage Service):对于需要长期归档或进行大数据分析的死信消息,可以直接将其存入S3。
- 优势:
- 成本极低:是长期存储大量数据的最佳选择。
- 便于分析:可以轻松地使用Amazon Athena、Amazon Redshift Spectrum等工具,直接对存储在S3上的死信数据进行SQL查询和分析。
- 优势:
4.2. 动态保留策略的云上实现
对于仍选择使用Kafka Topic作为DLQ的场景,可以利用AWS服务实现自动化:
- 创建CloudWatch Alarm:针对MSK的
KafkaDataLogsDiskUsed指标或DLQ消费者的EstimatedLag指标设置一个告警。当指标超过阈值时,该告警被触发。 - 触发SNS通知:CloudWatch告警向一个SNS Topic发送通知。
- 执行Lambda函数:一个专门的Lambda函数订阅该SNS Topic。当收到通知后,Lambda函数被触发。
- 调用Admin API:该Lambda函数使用Kafka AdminClient库(适用于Java, Python, Node.js等),以编程方式连接到MSK集群,并修改目标DLQ Topic的
retention.ms配置。
这个 CloudWatch -> SNS -> Lambda 的模式,是AWS上实现事件驱动自动化的经典方案。
4.3. 使用CloudWatch实现深度监控
上一章节提到的关键指标,在AWS上可以这样落地:
- DLQ消息瞬时增长率:在将消息发送到DLQ的消费者应用中,通过代码埋点,将“发送到DLQ的消息数”作为一个自定义指标(Custom Metric)上报给CloudWatch。然后可以对该指标的
SUM或RATE设置告警。 - DLQ消费者组延迟:如果DLQ是Kafka Topic,Amazon MSK会自动将所有消费者组的
EstimatedLag指标推送到CloudWatch,直接在控制台配置告警即可。如果DLQ是SQS,则监控ApproximateNumberOfMessagesVisible指标。 - DLQ主题磁盘占用:监控Amazon MSK自动提供的
KafkaDataLogsDiskUsed指标。 - Kafka Broker核心指标:Amazon MSK提供了丰富的Broker级别指标,如
CpuUser、MemoryUsed、NetworkTxBytes等,都可以在CloudWatch中直接监控和设置告警。
4.4. 弹性架构的云上实践
- 分层DLQ策略:可以利用不同的AWS服务实现分层。例如,
topic-dlq-immediate可以是一个SQS队列,由Lambda快速处理;而topic-dlq-manual则可以通过Kafka Connect的S3 Sink Connector,自动将消息沉淀到S3供后续分析。 - 生产者侧熔断机制:熔断器的状态(如
OPEN,HALF_OPEN,CLOSED)需要被所有生产者实例共享。可以使用 Amazon ElastiCache for Redis 或 Amazon DynamoDB 作为一个高速、低延迟的中央存储,来保存和同步熔断器的状态。 - DLQ消费者自动伸缩:这是AWS的强项。
- 如果使用SQS作为DLQ:将一个Lambda函数作为SQS的消费者。AWS会自动根据队列中的消息数量,秒级弹性伸缩Lambda的并发实例数,无需任何手动配置,这是最高效、最推荐的方案。
- 如果使用Kafka Topic作为DLQ:可以将您的消费者应用容器化,并部署在 Amazon ECS 或 EKS 上。然后,使用 Application Auto Scaling,配置一个伸缩策略,让它根据CloudWatch中的消费者Lag指标,自动增加或减少ECS任务或EKS Pod的数量。
5. 总结:重新审视“永不失败”的组件
DLQ是一个强大的工具,但绝非“一劳永逸”的银弹。这次事故最深刻的教训是:在分布式系统中,任何组件,包括那些为处理失败而设计的组件,其本身都可能成为故障点。
我们必须以审视核心业务组件的严格标准,来审视我们的“安全网”。为DLQ做容量规划、建立极限场景下的应急预案、并为其配备自己的“安全网”(如熔断器和动态策略),是确保整个系统在风暴中依然能够屹立不倒的关键。尤其在云环境中,善用云服务提供的自动化和弹性能力,是构建下一代高可用系统的核心。
6. 参考文档
- Apache Kafka 官方文档: https://kafka.apache.org/documentation/
- Amazon MSK 开发者指南: https://docs.aws.amazon.com/msk/latest/developerguide/what-is-msk.html
- AWS Lambda 与 SQS 集成: https://docs.aws.amazon.com/lambda/latest/dg/with-sqs.html