LLM大模型推理优化:一套系统化的全栈工程方法
LLM大模型推理优化:一套系统化的全栈工程方法
引言:从全功能AI平台到LLM推理优化的深度聚焦
本文的探讨,源于我对研发的AI机器学习平台的工作总结和持续迭代的工作思考以及业界对于LLM模型推理的诉求重视程度越来越高:一个基于GPU集群、对象存储和数据加速层(如Alluxio)构建底层基础设施,以云原生技术为PaaS核心,并深度整合了Argo Workflows与MLflow等CRD/Operator来打造自动化流水线,最终通过前后端分离的SaaS架构,为用户提供模型训练、推理、部署及资产管理等一站式服务的现代化AI机器学习平台。
在这个功能完备的平台上,我们发现,大型语言模型(LLM)的推理服务,相比于传统机器学习模型,呈现出截然不同的性能瓶颈和运维挑战。它不再是单一环节的优化问题,而是一个贯穿硬件、云原生平台、服务框架乃至模型算法本身的、高度耦合的系统性工程。
因此,本文将在这个真实的平台背景下,暂时收敛视角,专注于“LLM推理优化”这一垂直但至关重要的领域。我们将采用“系统分层、功能解耦”的架构思想,自底向上地对整个LLM推理服务栈进行一次全面的、系统性的梳理与解析,旨在为您呈现一幅从基础设施到模型算法、从理论到实践的、完整的LLM推理优化全景图。

LLM推理优化是一项典型且复杂的全栈系统工程,它的成功绝非任何单一角色或单一层面优化的结果,而是需要从基础设施工程师到软件架构师、从平台架构师到算法科学家的紧密协同与深度对话。为了更清晰地指引在真实团队中的落地实践,我们将整个优化栈的职责归纳为以下矩阵:LLM推理平台优化职责分配矩阵 (Responsibility Assignment Matrix)
| 角色 (Role) | 核心优化职责与关注点 (Core Optimization Responsibilities & Focus Areas) |
|---|---|
| 基础设施工程师(Infrastructure Engineer)-我在研发AI机器学习平台中的职责 | 物理基础的建设者:- 硬件选型与部署:负责GPU服务器的选型、部署和物理网络拓扑(NVLink, InfiniBand/RoCE)的规划与实现。- 存储加速:部署和运维如Alluxio、JuiceFS等分布式缓存系统,确保模型和数据能被高速读取。- 驱动与固件:维护NVIDIA驱动、网卡固件等底层软件栈的稳定与性能。 |
| 云原生平台架构师(Cloud-Native Platform Architect),我在研发机器学习平台中的职责 | PaaS平台的构建者与维护者:- K8s集群管理:负责Kubernetes集群的搭建、高可用维护和多集群联邦(Karmada)。- 高级调度:集成并配置如Volcano等批处理调度器,实现公平共享和组调度。- 标准化服务:部署和管理KServe,为上层提供统一、标准的模型服务能力,并集成Serverless基础设施(Knative)。- 资源虚拟化:配置和管理GPU的虚拟化方案(MIG, 时间分片)。 |
| SaaS平台软件架构师(SaaS Platform Software Architect),我在研发机器学习平台中的职责 | 用户体验与平台软件的设计者:- SaaS应用架构:设计和开发前后端分离的AI平台软件本身,提供模型管理、一键部署、监控告警等用户界面和API。- AI网关:负责AI网关(如Envoy AI Gateway)的设计、选型与扩展开发,实现智能路由、动态Batching和Token流控等高级功能。- MLOps/AIOps:设计和实现与Argo/MLflow等集成的CI/CD/CT流水线,打通从代码到服务的全流程自动化。 |
| 算法科学家/研究员(Algorithm Scientist/Researcher),我努力学习中 | 模型效率的源头:- 架构创新:研究和设计更高效的模型结构,如专家混合(MoE)、分组查询注意力(GQA)等。- 模型压缩:应用量化(QAT/PTQ)、剪枝、知识蒸馏等技术,从根本上减小模型的体积和计算量。- 前沿算法探索:探索如推测解码等新算法,以更低的成本获得更优的性能。 |
| 机器学习/应用工程师(ML/Application Engineer),我和机器学习应用工程师一起协作 | 模型到服务的“最后一公里”:- 服务封装:编写符合规范的Dockerfile,构建轻量、高效的容器镜像。- 推理后端选型:根据模型特点,在KServe中选择最优的推理运行时(vLLM, TGI, Triton等)。- 性能调优:精细化配置服务的健康探针、资源请求(requests/limits),并进行具体的性能测试与分析。- 业务逻辑集成:将推理服务API与上层业务应用进行集成。 |
1. 基础设施层 (Infrastructure Layer): The Foundation of Performance
这一层是所有性能的物理基石。在大规模AI场景下,它不仅关乎计算和网络硬件本身,更关乎如何高效地将数据(模型权重、数据集)送达计算单元。
1.1. GPU集群与硬件选型 (GPU Cluster & Hardware Selection)
- 计算卡选型:根据模型规模和成本预算,选择合适的GPU(如NVIDIA A100/H100/L40S)。关键指标包括算力(FLOPS)、显存容量(VRAM)和显存带宽(Memory Bandwidth)。解码阶段对显存带宽极为敏感,是选型的重中之重。
- 网络拓扑:GPU间的通信效率直接决定了分布式推理的性能。
- 节点内 (Intra-Node):高速的 NVLink 总线是张量并行(Tensor Parallelism)的理想选择,能支撑其频繁的All-Reduce通信。
- 节点间 (Inter-Node):高速的 InfiniBand (IB) 或 RoCE (RDMA over Converged Ethernet) 网络对于需要跨节点部署的巨型模型至关重要,主要服务于通信频率较低的流水线并行(Pipeline Parallelism)。
1.2. 存储加速与数据编排 (Storage Acceleration & Data Orchestration)
- 挑战:模型权重(特别是对于MoE等巨型模型)和训练/微调数据集通常存储在远端的对象存储(如S3, HDFS)中。在服务启动或扩容时,将这些动辄上百GB的数据通过标准网络传输到每个计算节点,会造成分钟级的延迟,严重影响冷启动速度和弹性效率。
- 解决方案:分布式缓存层:引入Alluxio或JuiceFS等数据加速和编排系统,在计算集群和底层持久化存储之间构建一个高速的分布式缓存层。
- 工作原理:这些系统能将远端存储的数据(模型文件、数据集)智能地、分布式地缓存到计算节点本地的内存、SSD甚至GPU内存中。当Pod需要读取模型时,它可以直接从本地或邻近节点的高速缓存中获取,而不是从远端存储拉取,实现“数据随计算而动”。
- 核心优势:
- 加速模型加载:将模型加载时间从分钟级降低到秒级。
- 统一数据访问:为上层应用提供统一的数据访问接口(如POSIX兼容的文件系统),屏蔽底层异构存储的复杂性。
- 提升数据密集型任务效率:不仅对推理,对未来的在线/离线微调(Fine-tuning)等需要反复读取大规模数据集的场景,提升效果更为显著。
2. 平台与调度层 (Platform & Scheduling Layer): The Brain of Resource Management
这一层负责将底层的物理资源虚拟化,并智能地分配给上层应用。随着AI平台规模化,它逐渐从单个Kubernetes集群管理演进为面向大规模、多集群的资源调度与治理。
2.1. 容器编排 (Orchestration)
- Kubernetes 已成为AI基础设施的事实标准。通过 NVIDIA GPU Operator 等插件,实现对GPU资源的发现、驱动安装和容器化环境的统一管理。
2.2. 面向AI的高级调度 (Advanced Scheduling for AI)
- 挑战:Kubernetes默认调度器(Default Scheduler)是为通用Web服务设计的,它以Pod为单位进行调度,缺乏对AI/HPC工作负载的理解。例如,它无法保证一个需要8个GPU的分布式训练任务的所有Pod能“同时”启动,容易导致部分Pod因等待资源而超时失败,造成资源死锁和浪费。
- 解决方案:批处理调度器 (Batch Scheduler):引入专为AI/HPC设计的调度器,如 Volcano。
- 核心能力:
- 组调度 (Gang Scheduling):确保一个作业(Job)所需的所有Pod必须同时满足资源要求后,才会被一起调度,实现“All-or-Nothing”的原子性操作。
- 公平共享 (Fair-share):在多租户/多团队环境中,根据预设的资源配额,在不同用户/队列间公平地分配资源,防止某个用户独占整个集群。
- 队列管理 (Queueing):允许为不同优先级的任务设置不同队列,保证高优任务能抢占资源,优先执行。
- 核心能力:
2.3. 多集群管理与联邦 (Multi-Cluster Management & Federation)
- 必要性:当GPU资源池增长到跨越多个K8s集群、多个区域(Region)甚至多个云厂商时,需要一个统一的“联邦大脑”来进行管理。
- 核心价值:实现跨集群的资源视图、应用分发和流量治理,以达到高可用性(HA)、故障隔离和避免厂商锁定等目的。
- 主流工具:
- Karmada: 华为开源的多集群应用编排引擎,提供了丰富的调度策略和故障转移能力。
- Clusterpedia: 一个能让你像使用Google一样搜索和关联多集群资源的工具,提供了强大的多集群可观测性。
2.4. GPU资源虚拟化与共享 (GPU Virtualization & Sharing)
- 资源切分:对于开发、测试或小模型推理等场景,使用 MIG(Multi-Instance GPU) 或 GPU时间分片(Time-slicing) 技术,可以将一张物理GPU卡虚拟化成多个小实例,允许多个Pod共享,从而极大提高昂贵GPU资源的利用率。
- 拓扑感知调度 (Topology-Aware Scheduling):调度器应感知物理网络拓扑,尽量将需要高频通信的Pod(如张量并行的各个实例)调度到同一台服务器,甚至是同一个NVLink域内,以最小化通信延迟。
2.5. 弹性伸缩 (Elastic Scaling)
- 核心技术:
- HPA (Horizontal Pod Autoscaler):根据CPU/内存或自定义指标(如GPU利用率)进行扩缩容。
- KEDA (Kubernetes Event-driven Autoscaling):根据消息队列长度、API网关流量等更丰富的事件源进行扩缩容,非常适合异步推理场景。
- Serverless GPU (如Knative):追求极致弹性,可从零启动并在空闲时缩容到零,最大化成本效益。
2.6. 标准化模型服务层 (Standardized Model Serving Layer): KServe
- 定位与价值:在Kubernetes和推理引擎之间,需要一个标准化的“服务层”来解决如何将模型文件部署为生产级服务的问题。KServe正是为此而生的、构建在Knative之上的开源模型推理平台。
- 核心抽象
InferenceServiceCRD:KServe将复杂的部署流程(如管理Deployment、Service、Ingress、HPA等)统一抽象为一个声明式的InferenceService资源。用户只需在一个YAML文件中定义模型的位置和所需的推理后端,KServe便会自动完成所有底层资源的创建和管理。 - 关键特性:
- 原生Serverless能力:由于构建在Knative之上,KServe为所有模型服务提供了开箱即用的**从零扩缩容(Scale-to-Zero)**能力。当没有流量时,服务Pod可以自动缩容到零,极大节约了昂贵的GPU资源成本;当流量到来时,又能快速冷启动服务。
- 可插拔的推理后端 (Pluggable Runtimes):这是KServe最强大的特性之一。它允许用户在
InferenceService的predictor定义中,自由选择不同的高性能推理框架作为后端。这意味着平台团队可以提供一套统一的部署和管理体验,而算法团队则可以为他们的模型选择性能最优的推理引擎,例如:runtime: vllmruntime: triton(可内嵌TensorRT-LLM)runtime: tgi
- 解耦与协同:KServe完美地将“如何部署(How to deploy)”和“如何运行(How to run)”这两个关注点解耦,让平台和算法团队能高效协同。
3. 服务与容器层 (Service & Container Layer)
这一层关注单个推理服务的封装和微观优化,核心是提升服务的启动速度和运行效率。
3.1. 容器镜像优化
(a) 减小体积 (常规优化):
- 使用 多阶段构建(Multi-stage builds),将编译环境和运行时环境分离。
- 选择轻量级的基础镜像(如
python:slim,alpine)。 - 清理不必要的依赖和缓存层。
(b) 采用镜像懒加载技术 (关键优化):
- 问题:AI/ML镜像通常包含巨大的模型权重和依赖库,体积可达数十GB。传统的容器启动流程需要先完整拉取整个镜像才能启动,导致冷启动时间极长(可达数分钟),严重影响弹性伸缩效率和开发迭代速度。
- 解决方案:镜像懒加载技术彻底改变了这一流程。它允许容器在镜像元数据下载完成后立即启动,而镜像内容(文件)则在首次被访问时才按需、分块地从远程仓库拉取。这是一种“先启动,后下载”的革命性模式。
- 核心技术与实现:
- Stargz (Seekable TAR Gzip): 由Google CRFS项目提出,是对标准OCI镜像格式的扩展。它通过在镜像层中添加一个“目录(TOC)”,使得可以对压缩包内的文件进行随机访问。
- Soci (Seekable OCI): 由AWS开源,它为现有的OCI镜像创建一个外部索引,无需重新构建镜像本身,降低了采纳门槛。
3.2. Pod健康探针的精细化配置
- GPU应用的启动过程通常较长(模型加载需要时间)。必须精细化配置Kubernetes的健康探针:
startupProbe(启动探针):给予Pod足够长的启动时间(例如5-10分钟),在此期间livenessProbe和readinessProbe不会生效,防止模型还未加载就被K8s误杀。readinessProbe(就绪探针):当模型成功加载到GPU并准备好接收流量时,此探针才应返回成功。这能确保流量只会被路由到真正可用的Pod上。livenessProbe(存活探针):用于检测服务是否陷入死锁等僵尸状态,其检测逻辑应轻量且可靠。
4. AI网关层 (AI Gateway Layer): The Intelligent Traffic Hub
作为所有推理请求的统一入口,AI网关的角色远不止是简单的流量转发。在LLM时代,它演变为一个智能的流量调度与治理中心,其设计的优劣直接影响整个系统的效率、成本和稳定性。
4.1. 传统网关的困境:为何Round-Robin在AI面前失效?
传统的API网关或负载均衡器(如Nginx、标准Envoy)通常使用轮询、最少连接数等策略。这些策略在无状态的Web服务中表现良好,但面对LLM推理这种有状态、资源高度敏感的工作负载时,则会“力不从心”:
- 缺乏负载感知:传统网关无法感知后端GPU的真实负载,如KV缓存的使用率、推理任务的排队长度等。这会导致请求被路由到已经过载的节点,而其他节点却处于空闲,造成资源浪费和延迟飙升。
- 无法理解LLM优化:它们不理解Prefix Cache(前缀缓存)的命中情况,也无法感知LoRA Adapter的加载状态,更不懂P/D分离架构的特殊路由需求。这使得很多上游的优化算法无法在网关层面得到配合,效果大打折扣。
- 请求同质化假设:它们假设所有请求都是相似的,但LLM的请求输入/输出长度差异极大,处理时间也完全不同,需要更精细的调度。
4.2. 现代AI网关的核心能力
为了解决上述问题,一个现代化的AI网关必须具备感知和处理AI特定信息的能力。以Envoy AI Gateway等前沿实践为例,其核心是通过可扩展的**端点选择器(Endpoint Picker)**机制,实现智能、动态的路由决策。
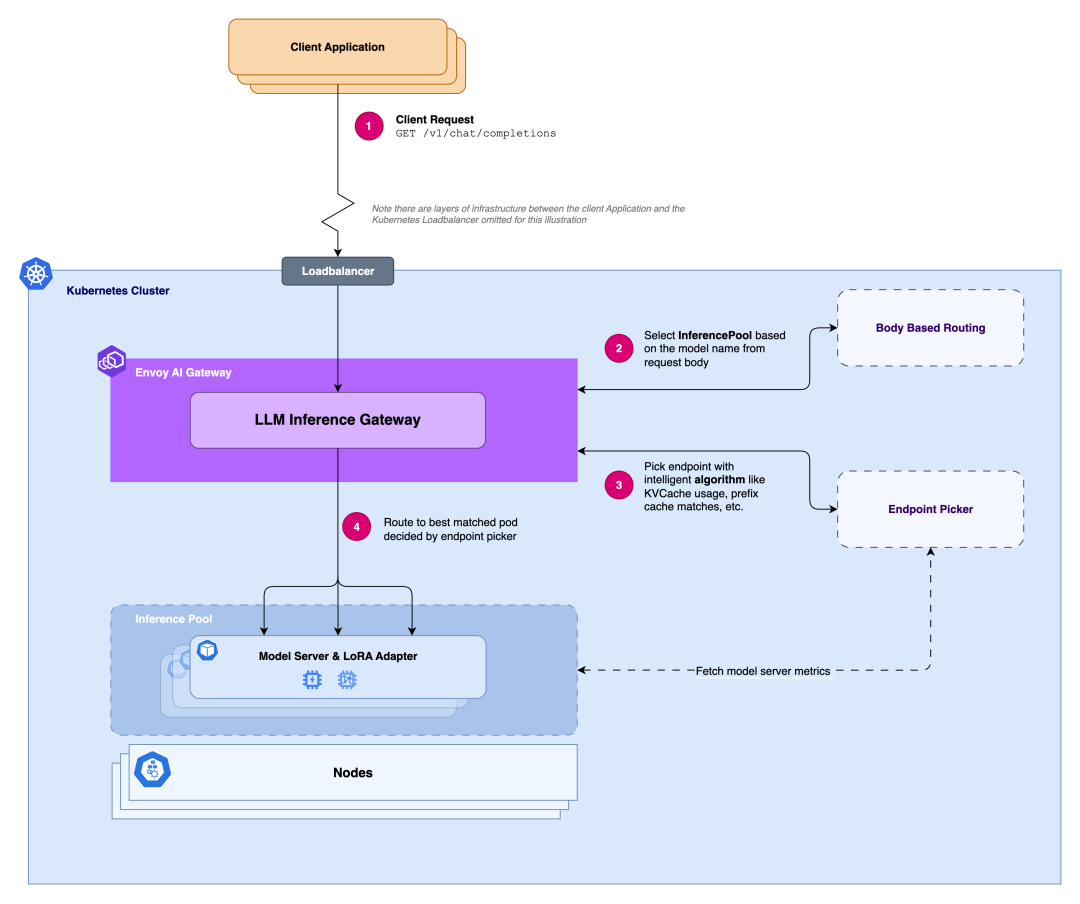
其关键能力包括:
智能负载感知路由 (Intelligent, Load-Aware Routing):
- 这是AI网关最核心的功能。它可以实时分析后端推理端点的各项指标,并将请求动态路由到“最优”的Pod。
- 关键指标:KV缓存使用率、推理排队请求数、GPU利用率、Prefix Cache命中率、LoRA Adapter亲和性等。
高级请求路由 (Advanced Request Routing):
- 支持通过自定义路由规则(如Envoy AI Gateway的
AIGatewayRouteCRD)解析请求内容,实现更灵活的路由。 - 能力:能根据请求头或请求体中的
model字段,将流量路由到不同的模型服务或版本,甚至可以混合路由到集群内的推理服务和外部的LLM API供应商。
- 支持通过自定义路由规则(如Envoy AI Gateway的
动态请求批处理 (Dynamic Batching):
- 在网关层收集短时间内到达的多个独立请求,合并成一个更大的批次(Batch),再发送给后端。这是在系统入口处提升整体吞吐量(TPS)的经典且有效的手段。
基于Token的成本控制与安全 (Token-based Cost Control & Security):
- 提供统一的API密钥管理、身份认证和访问控制。
- 关键能力:实现基于Token数量的速率限制(Rate Limiting),可以精细到对输入Token、输出Token或总Token进行限制,这对于成本控制和防止滥用至关重要。
统一可观测性 (Unified Observability):
- 作为统一入口,AI网关是收集LLM服务性能指标的最佳位置。
- 核心指标:提供TTFT、TPOT、Token使用量、端到端延迟等关键可观测性指标,帮助平台团队洞察不同模型的性能和成本。
结果缓存 (Result Caching):
- 对于高频、重复的相同Prompt,可以直接在网关层缓存并返回结果,避免后端重复计算。
5. 推理引擎与算法层 (Inference Engine & Algorithm Layer)
这一层是整个优化栈的核心,它直接决定了单次推理请求的计算效率。此处的优化可以分为三个主要层面:模型本身的优化、系统运行时的优化,以及分布式策略。它们共同决定了推理的最终性能。
5.1. 推理的本质:一个两阶段的自回归过程
现代LLM推理被清晰地划分为两个计算特性截然不同的阶段:
- 阶段一:预填充(Prefill):一次性并行处理用户输入的全部Prompt,是计算密集型(Compute-Bound),其速度受限于GPU的原始算力(FLOPS)。
- 阶段二:解码(Decode):逐一自回归地生成后续Token,是内存带宽密集型(Memory-Bandwidth Bound),其瓶颈在于从HBM中读写巨大的模型权重和KV缓存。
KV缓存是避免重复计算的关键优化,但其自身也带来了巨大的内存占用,成为现代推理优化的核心目标。
深入解析:什么是KV缓存 (KV Cache) 及其必要性
1. 它是什么? 在Transformer架构的自注意力机制中,为了计算每个Token的上下文表示,需要生成三个向量:查询(Query, Q)、键(Key, K) 和 值(Value, V)。注意力得分是通过当前Token的Q向量与所有历史Token的K向量进行点积计算得出的,然后用这些得分对所有历史Token的V向量进行加权求和。
KV缓存,就是将过去所有Token计算出的“键(Key)”和“值(Value)”向量存储在GPU的高速显存(HBM)中。
2. 为什么需要它? LLM的生成过程是自回归的。如果没有KV缓存,在生成第N+1个Token时,需要重新为前面N个Token计算K和V向量,造成巨大的重复计算。有了KV缓存,每一步解码都只涉及一次增量计算,而不是对整个序列的完全重计算,从而数量级地提升了LLM的解码速度。
结论:KV缓存是一种典型的空间换时间策略。管理和优化KV缓存的内存占用,是所有现代LLM推理框架的核心任务。
5.2. 核心性能指标
| 指标 | 定义 | 衡量内容 |
|---|---|---|
| 首个Token生成时间 (TTFT) | 从请求到收到第一个Token的时间。 | 系统的初始响应速度,由Prefill阶段决定。 |
| 每输出Token时间 (TPOT) | 平均生成每个后续Token的时间。 | 模型的“流式”生成速度,由Decode阶段决定。 |
| 延迟 (Latency) | 生成完整响应所需的总时间。 | 端到端的请求处理时间。 |
| 吞吐量 (Throughput) | 单位时间内处理的Token或请求总量。 | 系统的处理能力和成本效益。 |
5.3. 模型层面的优化:从架构创新到极致压缩
在算法和系统优化之前,最根本的优化来自于模型本身。这包括设计更高效的架构,或对现有模型进行压缩,使其更小、更快。
5.3.1. 架构创新 (Architectural Innovations)
注意力机制变体 (MQA/GQA):
- 标准多头注意力 (MHA):每个“查询头”都有一套独立的“键/值头”。
- 多查询注意力 (MQA):所有查询头共享同一套“键/值头”。这极大减小了KV缓存的大小,但可能导致一定的性能损失。
- 分组查询注意力 (GQA):一种折中方案,将查询头分组,组内共享“键/值头”。它在大幅减少KV缓存的同时,保持了接近MHA的性能,是当前的主流选择。
专家混合模型 (MoE, Mixture of Experts):
- MoE模型包含大量的“专家”(即小型的MLP网络)和一个“路由器”(Router)。在处理每个Token时,路由器会动态地选择激活一小部分(通常是2-4个)最相关的专家来进行计算。
- 优势:允许模型总参数量(知识容量)变得巨大,但单次推理的计算量(FLOPs)仅与被激活的少数专家相关。实现了“以更少的计算撬动更大的模型”。
推测解码 (Speculative Decoding):
- 使用一个小的、廉价的“草稿模型”快速生成一段候选文本(例如5个Token),然后让大的、昂贵的“主模型”进行一次并行的验证。如果验证通过,则一次性接受多个Token,从而用一次大模型的前向传播换来了多次常规的逐字解码,显著降低了端到端延迟。
5.3.2. 模型压缩技术 (Model Compression)
量化 (Quantization):
- 核心思想:降低模型权重和/或激活值的数值精度,如从FP32/FP16降至INT8、INT4甚至更低。
- 主要收益:显著减小模型体积(显存占用),降低访存带宽压力,并可利用现代GPU的专用低精度计算单元(如Tensor Core)来加速计算。
- 主要方法:
- 训练后量化 (PTQ):在模型训练完成后对其进行量化,简单快捷但可能有精度损失。
- 量化感知训练 (QAT):在训练过程中就模拟量化操作,让模型“适应”低精度,通常能获得更好的性能。
剪枝 (Pruning):
- 核心思想:移除模型中冗余或不重要的权重/结构。
- 主要方法:
- 非结构化剪枝:移除单个权重,会导致权重矩阵变得稀疏,需要专门的硬件或库才能有效加速。
- 结构化剪枝:移除整个神经元、通道甚至层,得到的模型依然是规整的稠密结构,对通用硬件更友好。
知识蒸馏 (Knowledge Distillation):
- 通过训练一个更小的“学生模型”,去学习一个强大的“教师模型”的输出(包括最终的概率分布和中间层的特征),从而将知识从大模型迁移到小模型,以期在更小的模型上获得相似的效果。
5.3.3. 面向资源受限场景的应用
在车载、移动端、边缘计算等场景,功耗、内存和延迟是压倒一切的制约因素。在这些场景下,上述模型压缩技术不再是“可选项”,而是“必需品”。通过综合运用量化、剪枝和蒸馏,可以将庞大的云端模型压缩成适合在资源受限设备上高效运行的轻量级版本。
5.4. 系统级运行时优化 (System-Level Runtime Optimizations)
对于一个给定的模型架构,系统层面的优化旨在最大化其在硬件上的执行效率。
- PagedAttention:受操作系统虚拟内存启发,将KV缓存分割成非连续的“页”,几乎完全消除了内存碎片,将内存利用率提升至最优,是vLLM等框架的核心技术。
- FlashAttention:一种IO感知的精确注意力算法,通过分块(Tiling)和核融合(Kernel Fusion)技术,最小化对GPU显存(HBM)的读写次数,极大加速了注意力计算。
- 连续批处理 (Continuous Batching):一种先进的调度策略,一旦批次中有请求完成,立即移出并加入新请求,确保GPU始终处于高负载状态,极大提升吞吐量。
5.5. 分布式推理策略与通信解密
当模型无法装入单卡时,必须采用分布式策略。其性能瓶颈往往在于GPU之间的通信。
- 并行策略:
- 张量并行 (TP):层内并行,将权重矩阵切分到多卡,通信开销大(All-Reduce),适合节点内高速NVLink。
- 流水线并行 (PP):层间并行,将不同层放到不同卡,通信频率低(Send/Receive),适合跨节点网络。
- 通信全链路解密:
- 算子触发:张量并行下的矩阵乘法算子,其拆分计算产生了对All-Reduce集合通信的需求。
- 库调用:上层框架调用NCCL库来执行All-Reduce操作。
- 硬件加速:NCCL利用RDMA技术,通过内核旁路和零拷贝,实现GPU间直接内存访问。
- 物理传输:RDMA指令最终在InfiniBand或RoCE等高性能网络上传输,完成数据交换。
5.6. 主流推理框架:将优化技术落地的“集大成者”
上述优化技术需要被一个高效的服务框架整合起来才能落地。主流框架正是扮演了这个“集大成者”的角色。
| 框架 | 主要优势 | 关键技术 | 最适用场景 |
|---|---|---|---|
| vLLM | 极致吞吐量,内存效率最高 | PagedAttention, 连续批处理 | 高并发在线服务,追求成本效益 |
| TensorRT-LLM | 极致低延迟,压榨硬件性能 | 编译器优化,算子融合,高级量化 | 对延迟敏感的业务,NVIDIA硬件环境 |
| Hugging Face TGI | 易用性,生态集成,稳定性 | Rust核心,多租户LoRA,开箱即用 | 快速原型与部署,多模型服务场景 |
5.7. 进阶架构:Prefill/Decode 分离、聚合与智能调度
在深刻理解了Prefill(计算密集)与Decode(访存密集)的两阶段特性后,社区探索出一种更激进的、旨在打破单一硬件瓶颈的架构——Prefill/Decode分离 (PD Separation)。这套方法论仍在持续演进,并衍生出更智能的调度与聚合模式。
5.7.1. PD分离的优缺点
- 核心思想:将Prefill和Decode阶段物理或逻辑地部署在最适合其特性的硬件上。
- Prefill集群 -> 使用高算力GPU(如H100),设置较小批次以保证低TTFT。
- Decode集群 -> 使用高带宽、较低算力的GPU(如L40S),设置较大批次以提升TPOT和吞吐量。
- 优势:
- 硬件专门化与成本优化:按需分配最合适的硬件,避免资源浪费,并可引入更具成本效益的推理卡。
- 独立优化:两个阶段的批处理大小(Batch Size)可以独立设置,打破了融合推理中的“均衡”难题。
- 劣势:
- 通信开销:最大的挑战。Prefill阶段计算出的KV Cache必须通过网络或总线传输到Decode节点,这引入了新的、可能极其显著的延迟瓶颈。
5.7.2. PD-Aware调度:让分离更智能
为了缓解通信瓶颈,单纯的物理分离演进为需要调度器感知的智能分离,即“PD-Aware Scheduling”。
- 工作原理:AI网关或上游调度器(如KServe的Orchestrator)不仅知道每个节点的硬件类型,还能实时感知其负载状态。当一个请求到来时,调度器会:
- Prefill阶段:将请求路由到一个当前负载较低、能快速处理Prefill的高算力节点。
- KV Cache传输:Prefill完成后,KV Cache被传输。
- Decode阶段:调度器根据实时负载(如队列深度、KV Cache占用率),将请求的Decode阶段路由到一个当前最空闲的高带宽节点。
- 核心价值:通过智能调度,避免了将Decode任务发送到已经过载的节点,从而优化了端到端的延迟,使分离架构的优势得以真正发挥。
5.7.3. PD聚合:最大化Decode吞吐量
在多租户或多LoRA模型的场景下,PD分离可以演进为一种更高效的模式——“PD聚合 (PD Aggregation)”。
- 架构模式:设置多个独立的Prefill组和一个或少数几个中心化的Decode聚合组。
- 多Prefill组:每个Prefill组可以专门处理一种模型、一个租户或一类请求。它们并发地处理各自的Prefill任务。
- 中心Decode聚合组:所有Prefill组完成计算后,都将生成的KV Cache发送到这个中心的Decode组。Decode组将来自不同源头的请求**动态地聚合成一个极大的批次(Mega Batch)**进行处理。
- 核心优势:
- 极致的Decode吞吐量:通过聚合来自多个源的请求,Decode阶段的批处理大小可以被推到硬件极限,极大地提升了TPOT和整体吞吐量。
- 高效的多模型/多租户支持:天然适合需要同时服务多种模型或多个用户的场景,是构建高效率多租户推理平台的理想架构之一。
5.7.4. 使能技术 (Enabling Technologies)
上述高级架构的实现,离不开底层技术的支撑:
- KV Cache量化:将KV Cache从FP16降至INT8/INT4,使其体积减半或更多,直接降低了PD分离中的网络传输开销。
- 混合执行/分层缓存:在同一服务器内部署不同类型的卡(如H100+L40S),通过高速NVLink/PCIe总线而非外部网络传输KV Cache,是一种高效的物理实现方式。
- 统一内存硬件:NVIDIA Grace Hopper (GH200)等新硬件,通过超高带宽的C2C总线将CPU和GPU内存统一,从根本上消除了传统意义上的“传输”瓶颈,是PD分离架构的理想硬件基础。
5.7.5. 工程决策:PD分离 vs. PD聚合的选型框架
在实际落地时,选择PD分离还是PD聚合(即传统的融合模式),并非一个普适性的“好坏”问题,而是一个高度依赖具体工程环境的权衡。以下是一个帮助决策的实践框架。
黄金法则:
- 选择PD分离:旨在实现规模化部署下的最大吞吐量和成本效益。可将其类比为“工厂流水线”,最适合需要同时为大量用户提供服务的高并发生产级系统。
- 选择PD聚合/融合:旨在在资源受限或高交互、低并发任务中实现最低延迟。可将其类比为“大师工作坊”,最适合实时聊天机器人、单用户体验或边缘计算部署。
决策速查表:
| 因素 | 选择PD分离,如果… | 选择PD聚合/融合,如果… |
|---|---|---|
| 主要目标 | 您需要最高的吞吐量(req/sec)。 | 您需要最低的延迟(TTFT)。 |
| 工作负载 | 您的Prompt很长(RAG)或生成很长。 | 您的Prompt和生成都很短且需要交互(聊天)。 |
| 硬件规模 | 您拥有带高速网络的大型集群(NVLink)。 | 您只有单台服务器、少数GPU或慢速网络。 |
| 复杂度 | 您的团队能管理一个复杂的分布式系统。 | 您需要一个简单、易于管理的部署方案。 |
最终建议:首先对您的应用进行性能剖析,了解工作负载特性和瓶颈。对于大规模服务,在PD分离上的工程投入几乎肯定会得到回报。对于延迟敏感的小型应用,PD聚合/融合是通往生产环境更安全、更快捷的路径。