K8s健康检查探针架构深度解析与最佳实践
前言
随着企业应用向容器化和Kubernetes平台迁移的不断深入,如何确保容器化应用的稳定运行,成为了平台SRE(网站可靠性工程师)与应用研发工程师共同面临的核心挑战。这不仅要求双方在软件开发编码和稳定性运维层面紧密协作,更需要对Kubernetes原生的高可用机制有深刻的理解和掌握。
我们注意到,当前团队对于Kubernetes健康检查探针(Liveness, Readiness, Startup Probes)的认知和实践尚显薄弱,这直接影响了我们应用的韧性和故障自愈能力。一个配置不当的探针,轻则无法发挥作用,重则可能引发服务中断的连锁反应。
为了弥补这一关键知识短板,并建立统一的最佳实践标准,我们组织了相关的技术培训,并将核心内容沉淀为本文档。本文旨在系统性地解析Kubernetes健康检查的架构、原理与最佳实践,为SRE和研发工程师提供一份清晰、可落地的行动指南,共同提升应用的稳定性和可靠性,确保在云原生道路上行稳致远。
K8s健康检查探针架构深度解析与最佳实践
1. 核心概念:理解健康检查架构
在深入探讨具体实现之前,我们必须首先理解Kubernetes健康检查的顶层架构。
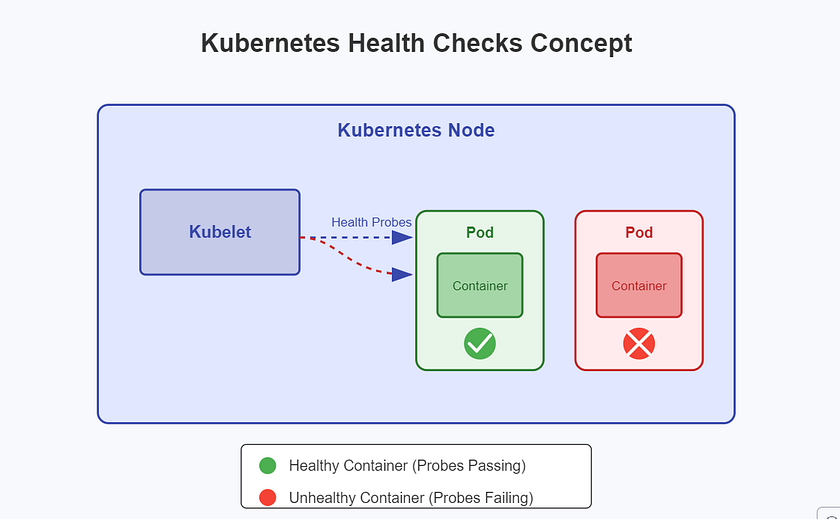
其核心机制是,每个节点上的kubelet(节点代理)会周期性地对运行在Pod中的容器执行健康检查。根据检查结果,Kubernetes能够自动化地采取补救措施,例如重启容器或将Pod从服务的后端Endpoint中移除。
这个机制的有效性完全取决于您如何设计和配置健康检查。糟糕的健康检查可能引发级联故障,而精心设计的健康检查则能极大地提升应用的韧性和用户体验。
2. K8s探针类型详解
Kubernetes提供了三种不同类型的健康检查探针,每种都在容器的生命周期中扮演着特定的角色。
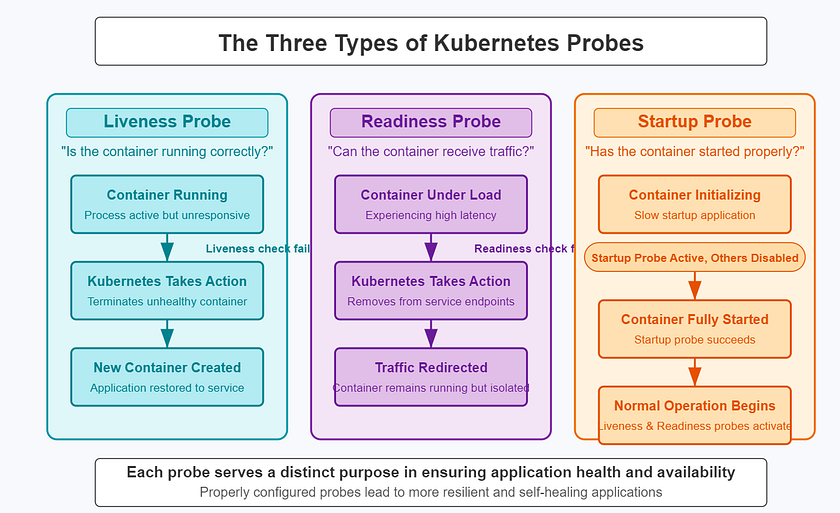
2.1. 存活探针 (Liveness Probes)
- 目的:判断容器是否正在正常运行。如果存活探针失败,Kubernetes会重启该容器。
- 核心价值:用于检测那些进程仍在但已无法正常工作的“僵尸”状态,例如:
- 应用程序代码中的死锁。
- 导致应用无响应的内存泄漏。
- 消耗过多CPU的无限循环。
- 无法通过重启之外的方式恢复的依赖服务故障。
2.2. 就绪探针 (Readiness Probes)
- 目的:判断容器是否准备好接收流量。如果就绪探针失败,Kubernetes会将其IP地址从所有关联的Service的Endpoint列表中移除。
- 核心价值:处理那些容器正常,但暂时无法提供服务的场景,例如:
- 应用启动时正在进行依赖初始化(如数据库连接、缓存预热)。
- 应用正在执行计划性任务,如数据库迁移或备份,期间需要临时拒绝流量。
- 应用正在进行优雅停机,需要先停止接收新流量,再处理完已有请求。
2.3. 启动探针 (Startup Probes)
- 目的:判断容器内的应用是否已经成功启动。在启动探针成功之前,所有其他的探针(存活和就绪)都会被禁用。
- 核心价值:专门为那些启动时间较长或不固定的应用设计,例如:
- 启动缓慢的遗留系统(如某些大型Java应用)。
- 需要加载大量数据或模型的应用。
- 在资源受限环境中启动,可能导致启动时间变长的应用。
2.4. 探针工作流
理解这三种探针如何按时间顺序协同工作,对于优化应用的生命周期行为至关重要。
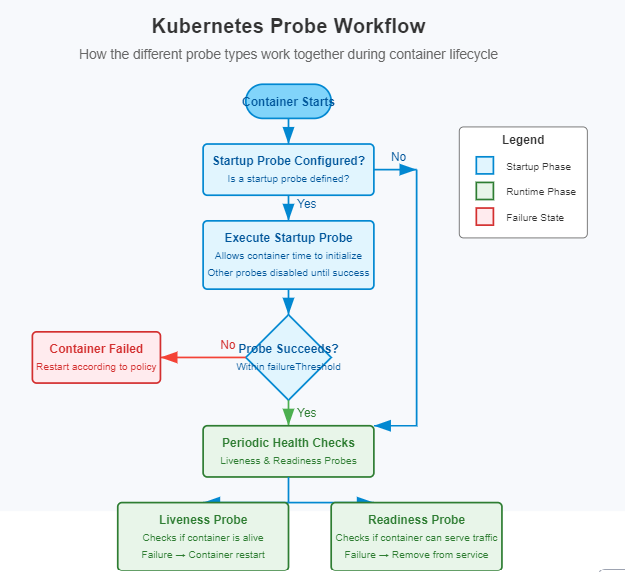
工作流决策树如下:
- 容器启动。
- 如果配置了启动探针,它将首先运行,直到成功或超出其
failureThreshold。 - 一旦启动探针成功(或者没有配置启动探针),存活探针和就绪探针将开始并行运行。
- 存活探针在容器的整个生命周期内持续验证其健康状况。
- 就绪探针则控制容器是否能从Service接收流量。
3. 探针应用指南:何时选择何种探针?
这是架构设计中的关键决策点,直接关系到应用的稳定性和可靠性。
3.1. 哪些应用需要使用探针?
简而言之,几乎所有长期运行的服务型应用(如Web服务器、API网关、后台服务、数据库等)都必须使用探针。
如果没有探针,Kubernetes只能在容器进程退出时(即PID 1进程终止)才知道应用出了问题。但大量的应用故障(如死锁、配置加载失败、依赖无法连接)并不会导致进程退出,此时应用已无法服务,但Kubernetes却认为它一切正常,依然将流量导向这个“僵尸”实例,从而引发用户侧的故障。
因此,为所有服务类应用配置探针是保障其达到生产级别稳定性的基本要求。
3.2. 哪些应用可以不使用探针?
只有少数特定类型的应用可以考虑不使用探针:
- 短期执行的批处理任务 (Jobs/CronJobs):这类任务的生命周期是“启动 -> 完成 -> 退出”。它们的成功与否由其最终的退出码(
0为成功,非0为失败)来判断。Kubernetes的Job控制器会根据退出码来决定任务是否成功。在这种模式下,存活探针通常是不必要的,甚至可能有害(例如,在任务长时间计算时重启它)。 - 极简的、无外部依赖的工具型容器:如果一个容器只是执行一个简单的、快速完成且不可能挂起的任务,也可以不配置探针。
注意:即使是批处理任务,如果其内部逻辑复杂,可能会挂起而不是失败退出,那么配置一个带有合理超时时间的存活探针也是一种好的防御性实践。
3.3. 哪些应用需要多探针组合?
绝大多数现代应用,尤其是微服务架构中的应用,都需要组合使用多种探针,以实现精细化的健康管理。
以下是典型的需要组合使用探针的场景:
有启动过程的Web应用(最常见):
- 需要组合:
启动探针+存活探针+就绪探针。 - 说明:
启动探针:应对应用启动时需要预热缓存、初始化数据库连接池等耗时操作。设置一个较长的failureThreshold,确保应用有足够的时间完成启动,避免被存活探针过早“杀死”。存活探针:启动完成后,存活探针接管,用于检测应用是否发生死锁等内部致命错误。它的检查逻辑应该轻量且不依赖外部服务。就绪探针:同样在启动后接管,用于检测应用是否能处理业务。它的检查逻辑应该更深入,例如检查与数据库、缓存、其他微服务的连接是否正常。如果数据库连接断开,就绪探针失败,流量被切走,但存活探针依然成功,容器不会被重启,给了数据库恢复的时间。
- 需要组合:
依赖外部服务的应用:
- 需要组合:
存活探针+就绪探针。 - 说明:这是区分“死”与“病”的经典模式。
存活探针:检查应用自身是否健康(如内存、线程池),不应检查外部依赖。就绪探針:检查对所有关键外部依赖(数据库、消息队列、第三方API)的连通性和健康状况。当外部依赖故障时,应用通过就绪探针将自己标记为“未就绪”,从而被动地从流量中隔离出来,实现了优雅的服务降级和故障隔离,防止级联故障。
- 需要组合:
需要执行维护任务的应用:
- 需要组合:
就绪探针。 - 说明:应用可能需要临时下线以执行数据库迁移、数据同步等任务。此时,可以通过一个API来控制就绪探针的返回状态。当任务开始时,让就绪探针返回失败,流量就会自动排空。任务结束后,再恢复就绪探针的成功状态,流量会重新进入。整个过程无需重启容器。
- 需要组合:
4. 探针实现:代码与配置的协同
探针的有效性依赖于**声明式的配置(YAML)和命令式的应用逻辑(代码)**之间的紧密配合。
- 配置 (YAML):定义了Kubernetes何时 (when)、如何 (how) 以及对什么 (what) 执行检查。
- 代码 (Application Code):提供了被检查的目标 (target),并封装了判断自身是否健康的逻辑 (logic)。
4.1. 协同模式
HTTP GET 探针(最常用)
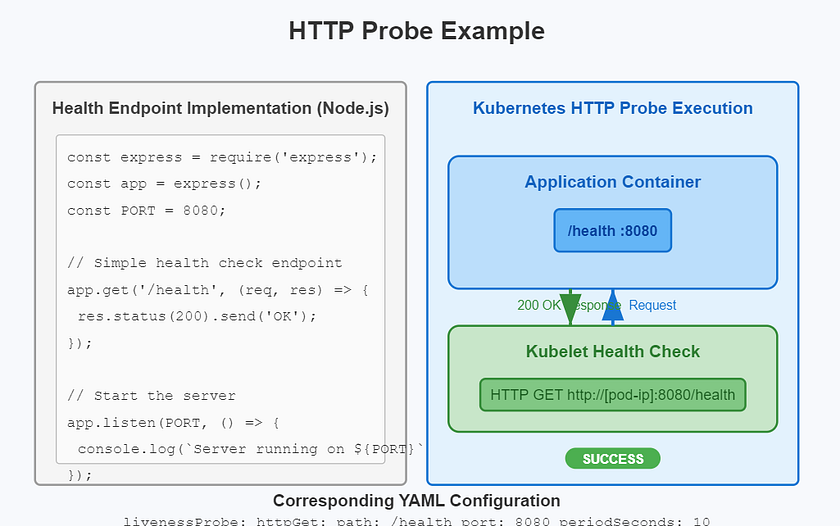
这是Web服务最理想的协同模式。
配置 (YAML):
livenessProbe: httpGet: path: /health/liveness # 检查哪个API端点 port: 8080 # 检查哪个端口 initialDelaySeconds: 15 periodSeconds: 10 readinessProbe: httpGet: path: /health/readiness port: 8080 initialDelaySeconds: 5 periodSeconds: 5代码 (例如 Node.js/Express): 应用必须实现
YAML中指定的/health/liveness和/health/readiness这两个API端点。// Express.js 示例 // 存活探针端点:只检查应用内部的关键功能 app.get('/health/liveness', (req, res) => { const isProcessHealthy = checkCriticalProcesses(); // 例如检查内部线程池是否正常 if (isProcessHealthy) { res.status(200).send('OK'); } else { res.status(500).send('Critical process failure'); // 返回500,探针失败 } }); // 就绪探针端点:检查内部健康状况和所有外部依赖 app.get('/health/readiness', (req, res) => { const dependenciesHealthy = checkDependencies(); // 例如检查数据库和缓存连接 if (dependenciesHealthy) { res.status(200).send('Ready'); } else { res.status(503).send('Not ready, dependencies unavailable'); // 返回503,探针失败 } });协同关系:
kubelet根据YAML中的periodSeconds,周期性地请求http://<pod-ip>:8080/health/readiness。应用代码中的app.get逻辑被触发,执行健康检查并返回HTTP状态码。kubelet根据状态码(200-399为成功)判断探针结果。
TCP Socket 探针
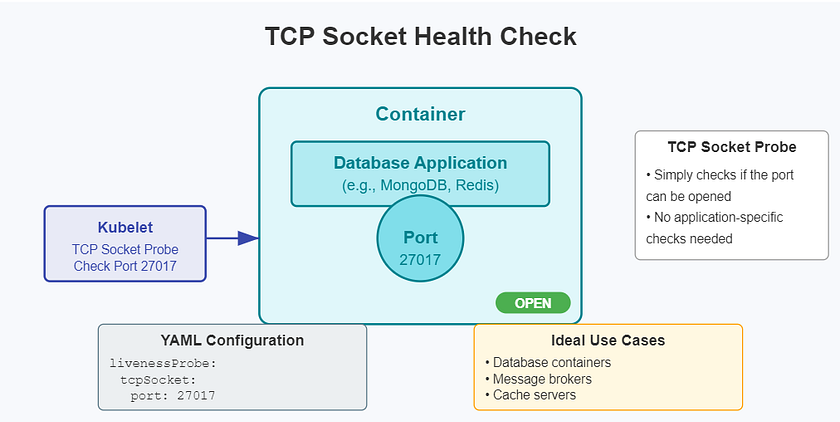
- 协同关系:这是最简单的协同。
YAML中只需指定端口。应用代码需要做的仅仅是监听该端口。kubelet会尝试与该端口建立TCP连接,只要连接成功,探针就成功。它不需要应用实现任何特定的API,但缺点是检查深度非常浅,只能判断端口是否可达。
Exec 命令探针

协同关系:
YAML中定义一个在容器内部执行的命令。应用代码或容器镜像需要提供这个命令或脚本。kubelet执行该命令,并根据其退出码是否为0来判断探針是否成功。readinessProbe: exec: command: - /bin/sh - -c - "pg_isready -U postgres" # 容器内必须包含 pg_isready 这个工具这里的协同在于,容器的
Dockerfile必须确保pg_isready这个工具被安装在镜像中。
4.2. 探针时间参数详解
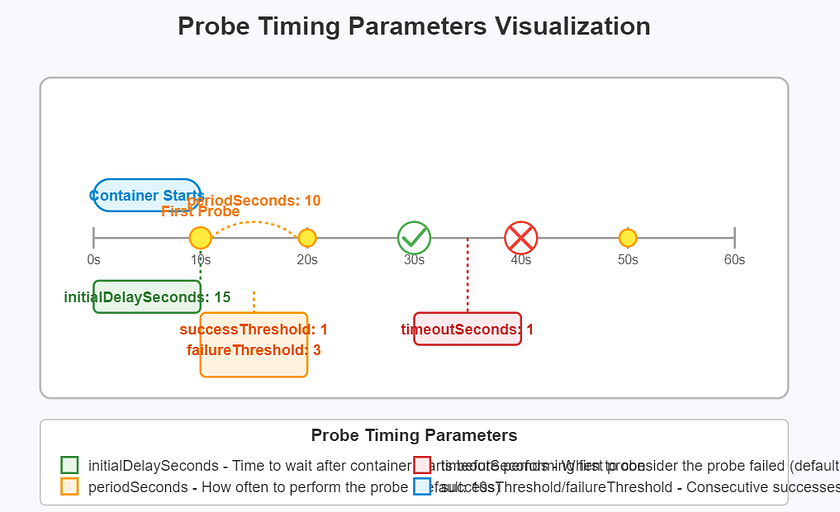
- initialDelaySeconds: 容器启动后,第一次执行探针前的等待秒数。
- periodSeconds: 执行探针的频率(秒)。
- timeoutSeconds: 探针超时的秒数。
- failureThreshold: 探针在被标记为失败前,需要连续失败的次数。
- successThreshold: 探针在失败后,被标记为成功前,需要连续成功的次数。
5. 开发最佳实践:在开发阶段集成健康检查
问题:是不是在代码开发阶段就要考虑适配代码的探针?
答案是:是的,绝对是。
将健康检查视为部署阶段(运维)的工作是一个常见的误区。健康检查端点的设计和实现是应用核心功能的一部分,必须在开发阶段就完成。 这体现了“谁开发,谁负责(You build it, you run it)”的DevOps文化。
为什么必须在开发阶段考虑?
- 定义“健康”的权利和责任在开发者:只有应用的开发者最清楚“正常工作”意味着什么。是数据库能连接?是缓存能读写?还是某个核心算法的线程池没有死锁?这些业务相关的健康标准无法由运维人员来定义。
- “可观测性”是内建能力:提供
/health、/metrics等端点是现代云原生应用“可观测性”(Observability)设计的基础。这应该像日志记录一样,成为编码的标准实践,而不是事后添加的补丁。 - 避免部署时的“意外”:如果在开发和测试阶段就没有相应的健康检查端点,那么在部署到Kubernetes时,要么无法配置有效的探针,要么配置的探针(如简单的TCP探针)无法真正反映应用健康,导致“僵尸”应用无法被发现。更糟糕的是,不恰当的探针配置(如过低的
initialDelaySeconds)会导致应用在生产环境陷入CrashLoopBackOff(无限重启)的循环,而这些问题本应在开发/测试环境就被发现和解决。 - 促进更健壮的架构设计:当开发者被要求为应用编写就绪探针时,他们会被迫去思考和梳理应用的所有关键依赖。这自然而然地会引导他们去思考如何处理依赖故障,例如实现断路器(Circuit Breaker)、回退机制(Fallback)等,从而设计出更具韧性的系统。
最佳实践:
- 代码模板化:在项目或团队的微服务代码模板中,默认就包含
/health/liveness和/health/readiness这两个API端点的骨架代码。 - 分层健康检查:在代码中实现分层的健康检查,例如一个总的
/health端点可以聚合来自数据库、缓存、消息队列等不同组件的健康状况。 - 优雅停机:除了探针,还应在代码中实现
SIGTERM信号的处理器,以配合Kubernetes的preStop生命周期钩子,实现优雅停机。
6. 常见健康检查问题排查

6.1. CrashLoopBackOff:因过早的存活探针导致
- 症状: 容器反复重启,日志显示应用尚未完成初始化。
- 解决方案:
- 增加存活探针的
initialDelaySeconds。 - 实现一个启动探针,这是最佳实践。
- 检查资源限制是否导致启动缓慢。
- 增加存活探针的
6.2. Pod就绪但应用不工作
- 症状: 服务端点返回错误,但
kubectl get pods显示Pod为Ready。 - 解决方案:
- 增强就绪探针的逻辑,让它检查关键的外部依赖(数据库、其他API等)。
- 不要只检查简单的HTTP 200,要确保业务逻辑也能正常工作。
7. 精心设计的健康检查带来的影响
- 增加正常运行时间 (Uptime)
- 减少平均恢复时间 (MTTR)
- 降低运维开销
- 提升用户体验
8. 建立全面的监控
除了探针,还应使用Prometheus等工具监控健康检查端点本身:
- 成功/失败率
- 响应延迟
- 关联应用指标:将健康状况与错误率、延迟等核心指标关联分析。
9. 真实世界示例:综合健康检查实施
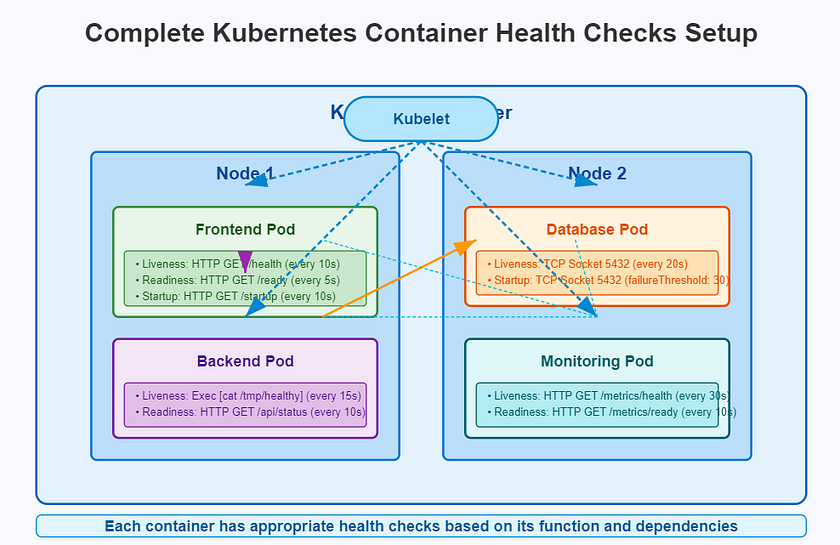
在一个典型的微服务架构中:
- 前端 Pod: 使用全部三种探针。就绪探针检查后端API连通性。
- 后端 Pod: 存活探针检查自身,就绪探针检查数据库连通性。
- 数据库 Pod: 使用TCP探针检查端口,使用
pg_isready等工具进行就绪检查。
10. 总结
- 探针是必需品:对于生产环境的长期服务,健康检查探针不是可选项,而是必需品。
- 按需组合:根据应用的启动特性和依赖关系,灵活组合使用
启动、存活、就绪三种探针。 - 协同设计:探针的威力来自于
YAML配置和应用代码的协同设计,开发者必须提供有意义的健康检查端点。 - 左移思想:健康检查的适配必须“左移”到开发阶段,将其作为应用的核心功能来设计、实现和测试,这是构建可靠云原生应用的关键。
通过遵循这些原则和实践,我们可以构建出真正具备自愈能力、高可用性的云原生应用,从而在激烈的市场竞争中保持技术领先。