Agentic AI 架构与生产实践指南
Agentic AI 架构与生产实践指南
摘要
Agentic AI,即AI代理或智能体,正迅速成为继大型语言模型(LLM)之后,推动人工智能应用走向深入的又一核心技术。与传统的机器学习或简单的LLM调用不同,Agentic AI系统能够自主或半自主地为了一个目标而进行规划、调用工具、观察结果、并迭代思考,直至达成目标。本文档旨在提供一份关于构建生产级Agentic AI系统的实用、全面的技术指南,内容涵盖其核心定义、架构蓝图、主流实现方案(开源与云厂商)对比、以及贯穿设计、开发、部署和运维全过程的安全护金、可观测性和生产落地考量。
1. 什么是Agentic AI及其应用场景
1.1. Agentic AI的定义
下图是Agentic AI的演进路线图:
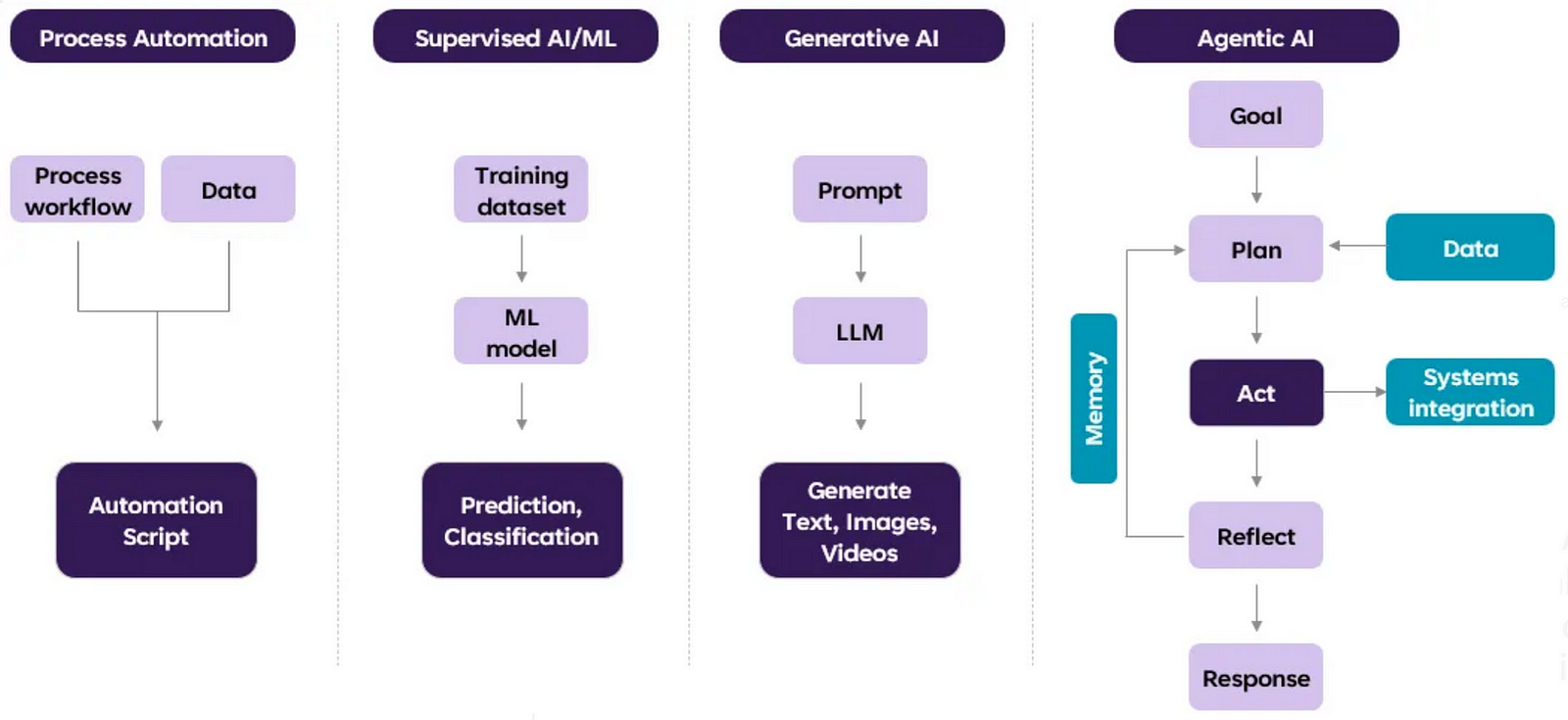
Agentic AI架构是一种软件系统范式,其核心是一个能够自主或半自主的智能体(Agent)。这个智能体为了达成一个高阶目标,会执行一个持续的控制循环(Control Loop):
- 规划 (Plan):将宏观目标分解为一系列可执行的步骤(例如,“查询订单 → 核对退货策略 → 起草解决方案”)。
- 行动 (Act):调用一个或多个**工具(Tools)**来执行具体步骤,如请求API、查询数据库、运行代码等。
- 观察 (Observe):捕获行动的结果以及任何副作用。
- 反思/决策 (Reflect/Decide):验证输出结果,更新其内部的记忆/状态(Memory/State),然后决定是进行下一轮迭代,还是任务已完成并终止。
在整个循环中,智能体始终受到**安全护栏(Guardrails)**的约束,确保其所有行为都合规、安全、且在预算范围内。
1.2. 应用场景
传统的机器学习系统在输入和输出固定的任务上表现出色。然而,现代企业面临的问题通常是开放式的,需要整合多个数据源,并有严格的合规要求。Agentic AI架构正是为此而生。
- 智能客户支持:一个AI客服代理接收到“我的订单为什么还没到?”的请求。它会规划并执行:1. 调用订单系统API查询订单状态;2. 调用物流系统API查询包裹位置;3. 调用知识库查询最新的物流时效策略;4. 综合所有信息,生成一个完整、个性化的答复给用户。
- 自动化交易对账:一个财务代理被要求“核对Q3季度所有来自供应商A的发票与支付记录”。它会分别调用发票系统和支付系统的API,获取数据,逐一比对,并将差异项整理成报告,最后提交给人类财务专员进行复核。
- 动态的DevOps管理:一个运维代理监测到生产环境某服务延迟飙升。它会自动执行诊断流程:1. 从Prometheus拉取该服务的性能指标;2. 从Loki查询相关错误日志;3. 检查ArgoCD获取最近的部署记录。最后,它向运维工程师报告:“服务延迟因新版本v1.2的数据库连接池配置错误导致,建议回滚到v1.1。”
1.3 一些项目实践
我的GitHub上有一些相关实践可以参考:
- Dify on Dingtalk项目: Dify-on-Dingtalk 是一个轻量级的桥接服务,可将您的 Dify 应用与钉钉机器人无缝集成
- AI新能源汽车分析助手: 基于CrewAI多智能体框架和DeepSeek大模型的新能源汽车行业分析系统,可以自动收集、分析新能源汽车相关新闻并生成详细的分析报告。
- AWS 云工程师智能助手: 使用 Strands Agents SDK 构建的强大的 AWS 云工程师智能助手,展示了如何使用模型优先的方法轻松创建复杂的 AI 代理。该助手可以在 AWS 账户上执行各种云工程任务,如资源监控、安全分析、成本优化等。
- Bedrock AgentCore 部署实践项目 : 基于 Python 和 LangGraph 的 AI 代理,通过容器化技术部署到 AWS Bedrock AgentCore。它为您提供了一个从本地开发到生产环境部署的完整蓝图,解决了 AI 代理在生产环境中面临的安全、扩展和可观测性等核心挑战。
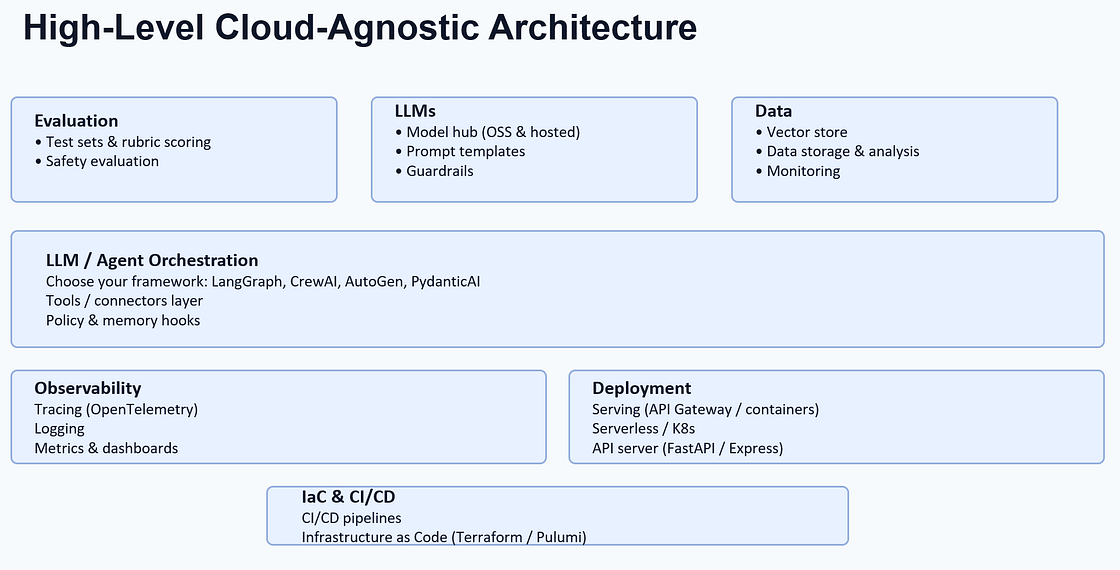
2. Agentic AI 核心架构蓝图
构建一个生产就绪的Agentic AI系统,通常需要以下核心组件。
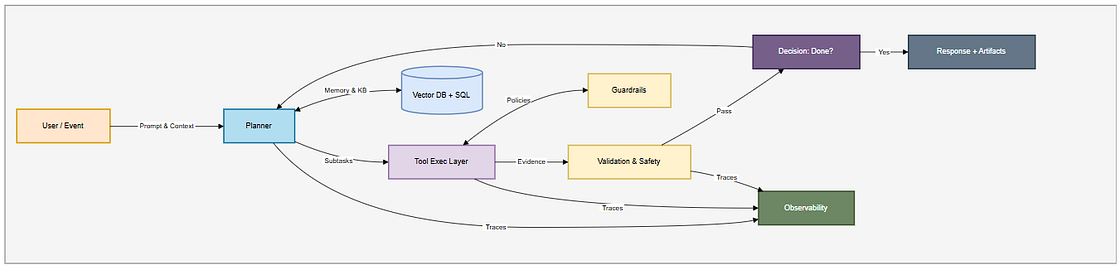
2.1. 核心组件与职责
- 入口/API层 (Ingress/API):系统的统一入口。负责处理认证(JWT/OAuth)、速率限制、配额管理、WAF防护,并为每个请求注入一个全局唯一的关联ID(Correlation ID)用于全链路追踪。
- 编排器 (Orchestrator):智能体的大脑和调度中心。它负责运行规划、管理状态、执行工具调用、处理重试和超时、并支持“人工审核(Human-in-the-Loop)”的暂停与恢复。这是Agentic AI框架(如LangGraph, CrewAI)的核心。
- 工具层 (Tools Layer):智能体可以调用的外部能力集合。每个工具都应被封装成一个具有明确输入/输出契约的适配器(Adapter)。工具的调用必须经过策略网关的强制检查(如权限、成本、速率)。
- 记忆层 (Memory Layer):为智能体提供记忆能力。
- 短期记忆:当前任务的上下文,如对话历史、规划状态。
- 长期记忆:通过RAG(检索增强生成)访问的知识库,通常是向量数据库(用于语义搜索)、SQL数据库(用于事实查询)或图数据库(用于关系推理)的混合体。
- 策略与护栏 (Policy & Guardrails):在系统的每个环节(输入、规划、工具调用、输出)强制执行规则。包括PII数据脱敏、内容安全过滤、工具使用权限、成本预算控制等。
- 验证器 (Validators):对智能体的所有输出进行确定性的检查,如数据结构校验(Schema Validation)、业务规则校验(如金额范围、日期有效性)等。
- 事件总线 (Eventing):将智能体执行过程中的所有关键事件(如规划步骤、工具调用、人工审批、最终结果)以不可变的日志形式,发布到事件流(如Kafka),用于审计、监控和离线评估。
- 可观测性 (Observability):通过统一的追踪ID,将分布在各个组件的日志(Logs)、指标(Metrics)、轨迹(Traces)串联起来,实现对智能体决策过程的端到端可视化。
2.2. 代理拓扑(Topologies)
根据任务的复杂性,可以选择不同的代理组织形式:
- 单代理 (Single-agent):适用于目标明确、边界清晰的单一工作流,如“总结这篇文档”。
- 分层代理 (Hierarchical):适用于多步骤、角色分明的流程。例如,一个“总管”代理负责规划,然后将子任务(如“调研”、“写作”、“评审”)分配给不同的“专家”子代理。
- 协作式代理 (Collaborative / Swarm):适用于需要从多个视角进行头脑风暴或综合分析的任务。例如,多个研究员代理分别从不同来源搜集信息,最后由一个“整合者”代理将所有观点汇总成一份报告。
3. 主流实现方案:开源与云厂商对比
选择一个合适的编排框架或平台,是Agentic AI项目成功的关键。
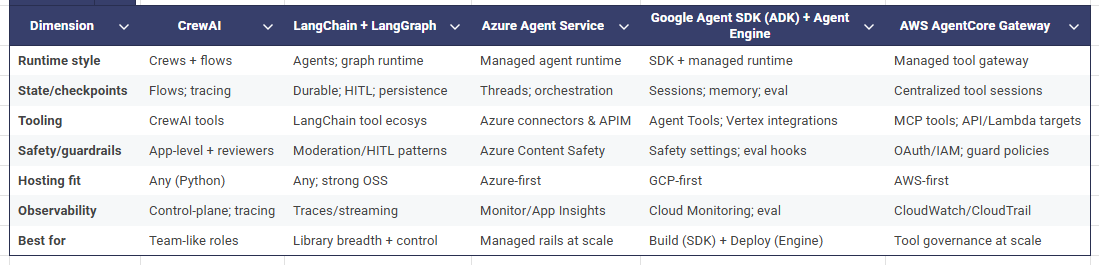
| 方案 | 类型 | 核心理念 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| LangChain/LangGraph | 开源框架 | 提供构建LLM应用的全套工具链和抽象。LangGraph专注于创建可靠、有状态的图状工作流。 | 需要高度定制化和灵活性的团队,希望掌控所有技术细节。 | 生态最丰富,灵活性极高,社区活跃。 | 学习曲线陡峭,版本迭代快,稳定性需自行保障。 |
| CrewAI | 开源框架 | 专注于多代理协作,强调基于角色的任务分配和流程自动化。 | 需要模拟人类团队协作流程的任务,如软件开发、内容创作等。 | 理念清晰,易于上手,能快速构建多代理系统。 | 功能相对聚焦,不如LangChain全面。 |
| Amazon Bedrock Agents | 云厂商方案 | 提供一个全托管的智能体构建和部署环境,深度集成了Bedrock模型、知识库(RAG)和工具调用(Lambda)。 | 希望在AWS生态内快速构建、部署和管理智能体的企业。 | 开箱即用,与AWS服务无缝集成,简化了运维。 | 灵活性受限于平台能力,有厂商锁定风险。 |
| Google Vertex AI (ADK + Agent Engine) | 云厂商方案 | 提供开源的Agent Development Kit (ADK)用于灵活构建,同时提供Vertex AI Agent Engine用于生产环境的托管、扩展和评估。 | 希望兼顾开发灵活性和生产级托管能力的GCP用户。 | 兼顾了开源的灵活性和云平台的稳定性与可扩展性。 | 相对较新,生态和最佳实践仍在快速发展中。 |
| Azure AI Studio | 云厂商方案 | 提供一个可视化的智能体构建和实验平台(Prompt Flow),深度集成Azure OpenAI服务和各类Azure工具。 | 希望利用可视化流程编排和微软生态构建智能体的企业。 | 可视化编排降低了门槛,与企业级Azure服务集成度高。 | 抽象层次较高,底层定制化能力可能受限。 |
4. 生产和落地考虑
- 安全与防护 (Security & Guardrails):这是生产落地的首要前提。必须在每一层都设置护栏:
- 输入端:进行PII数据检测与脱敏,并防御提示词注入攻击。
- 工具调用端:为每个工具配置最小权限的IAM角色或API密钥,并使用网络出口白名单限制其访问范围。
- 输出端:对生成的内容进行内容安全审查和PII数据二次检查。
- 执行环境:在安全的沙箱环境(如容器)中执行代码或命令。
- 可观测性与调试 (Observability & Debugging):Agentic AI的非确定性使其调试变得困难。必须采用类似 LangSmith 的**智能体追踪(Agent Tracing)**工具,可视化地展示每一步的思考链、工具调用和结果,以便快速定位问题。
- 评估与测试 (Evaluation & Testing):不能只做单元测试。需要构建一个“黄金评估数据集”,包含各种典型和边缘场景,在每次变更后自动运行评估,以防止性能和准确性的“静默衰退”。
- 人机协同 (Human-in-the-Loop, HITL):对于任何高风险或不可逆的操作(如执行付费、删除数据、部署应用),必须在工作流中设计一个“人工审批”节点。智能体运行到此节点时会暂停,等待人类批准后才能继续。
- 成本控制 (Cost Management):Agentic AI的“思考”过程(多步LLM调用)可能会产生高昂的Token费用。必须实施预算控制,例如:限制单个任务的最大思考步数、对高成本工具的调用进行限流、或在某些环节使用更小、更便宜的模型。
5. 专业问答 (FAQ)
Q1: “Agentic AI”和普通的“Chatbot”有什么本质区别?
A: 核心区别在于自主性和行动能力。传统Chatbot大多是被动地进行一问一答,其能力边界通常被RAG(知识库问答)所限制。而Agentic AI是主动的,它有明确的目标,能够自主地规划一系列步骤,并调用工具与外部世界进行交互来达成这个目标,它是一个“行动者”而不仅仅是一个“回答者”。
Q2: 为什么说“依赖注入(DI)”是工具层设计的关键?
A: 因为它将“能力”与“具体实现”解耦。智能体在规划时不应关心“我正在调用SendGrid的邮件API”,而只应关心“我需要使用send_email这个能力”。通过依赖注入,我们可以在不改变智能体核心逻辑的情况下,轻松地将邮件服务从SendGrid切换到SES,或在测试环境中注入一个Mock的邮件服务。这极大地提升了系统的可维护性、可测试性和厂商无关性。
Q3: 如何处理智能体执行任务失败或陷入死循环的情况?
A: 这是编排器(Orchestrator)的核心职责。一个生产级的编排器必须具备:
- 重试机制:为工具调用配置带指数退避的重试逻辑。
- 超时控制:为每一步乃至整个任务设置最大执行时间。
- 状态持久化:在关键步骤后持久化状态(Checkpoint),以便在系统崩溃后能从上一个节点恢复,而不是从头开始。
- 循环检测:检测智能体是否在重复执行相同的步骤,如果发现,则强制中断并上报错误。
Q4: 构建一个有用的Agentic AI应用,最关键的挑战是什么?
A: 技术上,最关键的挑战往往是可靠性和评估。即如何确保智能体在绝大多数情况下都能稳定、正确地完成任务,以及如何量化地评估它的表现。这需要投入大量精力来构建高质量的评估数据集、设计鲁棒的错误处理和回退逻辑,并建立起一套完善的、端到端的追踪和调试系统。
6. 参考文档
核心框架与云厂商方案
- LangChain/LangGraph: GitHub, Docs
- CrewAI: GitHub, Homepage
- Amazon Bedrock Agents: Product Page
- Google Vertex AI Agents (ADK): GitHub, Docs
- Azure AI Studio (Prompt Flow): Docs
安全与护栏
评估与可观测性
- LangSmith (by LangChain): Product Page
- Promptfoo: GitHub
- OpenTelemetry: Homepage