GPU集群在AI模型训练与推理中的核心作用与技术深度解析
前言
在当前的AI技术浪潮中,构建和运维一个高效、稳定的AI机器学习平台是释放算法价值的关键所在。作为平台研发的核心,GPU集群的管理与调度直接决定了模型生命周期的效率。本文是我在近期研发AI机器学习平台过程中的一份深度总结,旨在系统性地梳理和对比GPU集群在**模型训练(Training)和模型推理(Inference)**这两个核心阶段所扮演的截然不同的角色、面临的独特挑战以及各自的性能优化策略。通过本文,我希望能为从事平台工程、MLOps以及AI基础设施建设的同行提供一份清晰、实用的技术参考。
摘要
本文档旨在清晰地阐述并对比GPU物理集群在模型训练 (Training) 和模型推理 (Inference) 这两个核心AI生命周期阶段中所扮演的不同角色、面临的挑战及其相应的加速机制。
- 训练阶段的目标是缩短单一、庞大任务的完成时间,集群在此表现为一台统一的“超级计算机”,核心在于通过大规模并行计算,不惜一切代价缩短模型收敛时间。
- 推理阶段的目标是高效处理海量、独立的并发请求,集群则作为分布式的“高并发服务中心”,核心在于在满足低延迟的同时实现高吞吐量。
理解二者的差异对于设计、优化和部署高效、经济的AI基础设施至关重要。
一、 GPU集群对模型训练的加速作用:聚焦于缩短“完成时间” (Time-to-Train)
在训练阶段,我们面对的是巨大的数据集和日益复杂的模型。核心目标是通过并行计算大幅缩短模型从开始训练到最终收敛所需的时间。集群在此阶段的作用是“集中力量办大事”。
核心加速方式:大规模并行计算
数据并行 (Data Parallelism) - 最主流的应用
- 工作原理:将完全相同的模型副本分发至集群中的每一张GPU。同时,将一个大的训练数据批次(Batch)切分为N个小批次,每张GPU独立完成前向和后向传播,计算出各自的梯度。
- 集群的加速价值:最关键的步骤是梯度同步。所有GPU必须通过高速网络,高效地执行
All-Reduce等集合通信操作,将各自计算出的梯度进行聚合(如求和或平均),以获得全局一致的梯度。GPU集群配备的高速互联网络(如InfiniBand/RoCE + RDMA)和优化的通信库(如NVIDIA NCCL)是实现这一过程的生命线。它们能将GPU间的通信延迟降至最低,从而最大化并行计算的效率。
模型并行 (Model Parallelism) - 应对超大规模模型
- 工作原理:当模型大到单张GPU的显存无法容纳时,必须将模型的不同部分拆分到不同的GPU上。这主要包括:
- 张量并行 (Tensor Parallelism):将模型中的某一层(例如一个巨大的矩阵乘法)切分给多张GPU协同计算。
- 流水线并行 (Pipeline Parallelism):将模型的不同层(例如第1-10层给GPU-1,第11-20层给GPU-2)部署在不同的GPU上,形成计算流水线。
- 集群的加速价值:这两种模式都产生了大量的中间计算结果依赖。无论是中间激活值的交换,还是流水线层与层之间的输出传递,都极度依赖集群内部的高速、低延迟网络。任何网络上的延迟都会直接导致整个计算链路的停滞,即“流水线气泡”(Pipeline Bubble),从而降低训练效率。
- 工作原理:当模型大到单张GPU的显存无法容纳时,必须将模型的不同部分拆分到不同的GPU上。这主要包括:
训练阶段总结:
GPU集群通过其庞大的并行计算能力和极致优化的内部通信网络,将一个原本需要数月甚至数年的训练任务,压缩到数周或数天内完成。其核心衡量指标是训练吞吐量 (Throughput),即单位时间内能处理的数据样本量(如 samples/sec),以及随节点增加而带来的扩展效率 (Scaling Efficiency)。
二、 GPU集群对模型推理的加速作用:聚焦于“低延迟”与“高吞吐”
在推理阶段,场景转变为服务大量用户的实时请求。目标不再是完成一个单一的宏大任务,而是要同时满足两个核心服务质量(SLA)指标:单次请求的响应时间要足够短(低延迟, Low Latency),以及单位时间内能处理的请求数量要足够多(高吞吐量, High Throughput)。
2.1 推理阶段的核心挑战
大模型在实际应用中的运行成本和推理时间是两个必须考虑的重要因素。一方面,越来越庞大的模型需要更多的计算资源;另一方面,最终用户希望在推理时获得快速的响应时间。这带来了以下核心挑战:
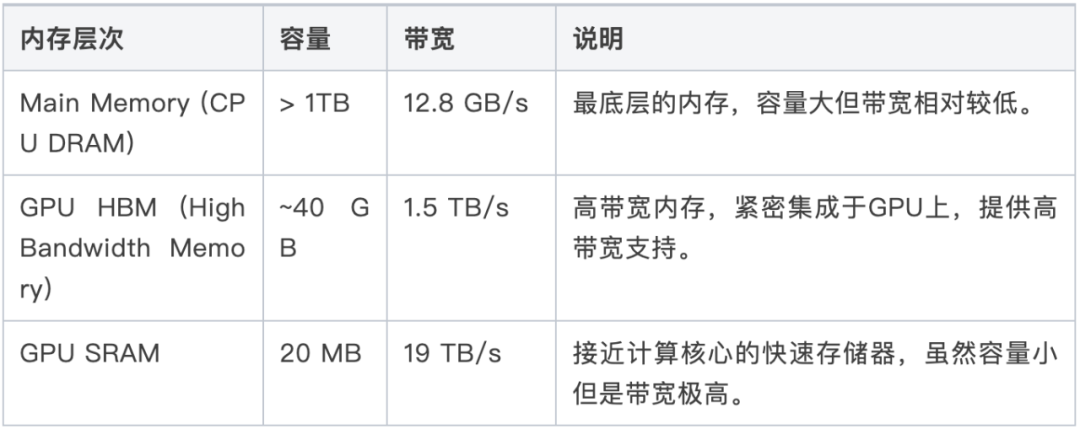
1. 高计算成本和内存需求
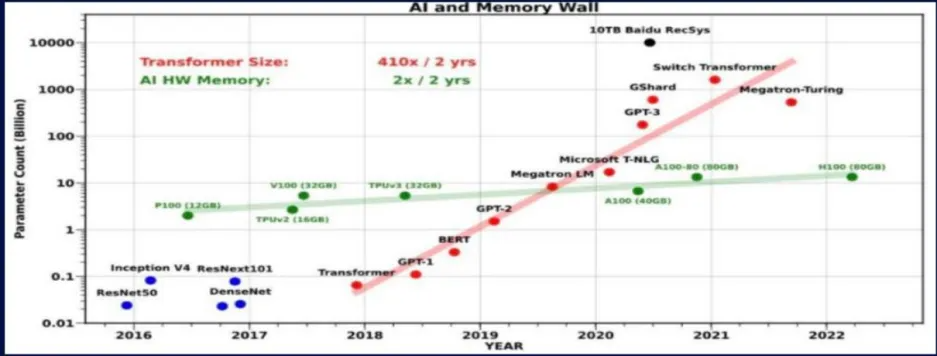
大模型通常拥有数十亿甚至上百亿的参数,这使得模型在推理阶段需要大量的计算资源和能耗。超大模型参数和超长序列是大模型的发展趋势,这使得大模型推理对计算和内存的需求日益增加。同时,模型参数的增长速度远快于硬件内存容量的提升速度,进一步加剧了推理中的内存瓶颈问题。
2. 延迟和吞吐量之间的权衡
- Prefill和Decode阶段的计算不均衡:大模型推理通常分为处理输入序列的Prefill阶段和逐个生成token的Decode阶段。Prefill阶段计算密集,而Decode阶段计算量小但访存频繁,导致GPU资源利用率在两个阶段间极不均衡。
- 自回归推理的低计算效率:在Decode阶段,逐token生成的方式导致计算多为GEMV(矩阵向量乘法),其计算密度远低于训练时的GEMM(矩阵矩阵乘法),难以充分发挥GPU的算力。
- 任务不均衡与调度困难:不同请求的输入和输出长度各不相同,使得高效的批量化(Batching)处理变得非常困难,加剧了资源利用的不均衡。
3. 从单模态到多模态的推理成本增加
随着模型从文本扩展到处理图像、音视频等,数据序列变得更长,计算量和显存需求呈指数级增长,进一步加大了推理成本和延迟。
2.2 推理阶段的核心加速方式
为应对上述挑战,GPU集群在推理阶段的核心加速方式聚焦于负载均衡、资源复用与并发处理。
高并发处理 (Handling High Concurrency) - 最主要的价值
- 工作原理:将同一个模型在集群中的许多张GPU上都加载一份,每一张GPU都构成一个独立的推理服务实例。在集群前端部署一个负载均衡器 (Load Balancer)。
- 集群的加速价值:当成千上万的请求同时涌入时,负载均衡器会将这些请求智能地分发到集群中不同的、空闲的GPU实例上进行并行处理。集群的价值在于提供了海量的、可独立工作的、可横向扩展的GPU服务池,从而能够同时服务大量用户,实现极高的总吞吐量(以
Queries Per Second, QPS衡量)。
巨型模型单次推理加速
- 工作原理:对于单个请求,如果模型本身巨大到一张GPU无法容纳或处理过慢,就需要像训练时一样,采用张量并行和流水线并行,由多张GPU协同完成一次前向传播。
- 集群的加速价值:此时,集群的高速网络再次发挥关键作用,其目标是尽可能降低单次请求的端到端响应时间(Latency)。通过多GPU的高效协作,将一次原本无法完成或耗时很长的推理,变得可行且足够快,以满足实时服务的需求。
动态批处理 (Dynamic Batching)
- 工作原理:GPU处理一个包含多个请求的批次(Batch),其效率远高于逐个处理单个请求。推理服务框架(如NVIDIA Triton Inference Server)可以在极短的时间窗口内(例如几毫秒),动态地将多个用户的独立请求**聚合(Batching)**成一个最优批次,再统一交给某一张GPU处理。
- 集群的加速价值:集群环境为动态批处理提供了充足的请求来源和处理能力,使得这一优化策略能够有效实施,从而极大提升单张GPU的利用效率和整个集群的吞吐量。
三、 推理加速技术深度解析
为了实现上述加速目标,业界发展出了一系列覆盖算子、算法到系统框架的全栈优化技术。
3.1 算子层优化 (Operator-Level)
算子融合 (Operator Fusion)
- 技术:将多个独立的计算算子(如
MatMul,Add,Softmax)融合成一个单一的、更复杂的CUDA核函数。 - 价值:显著减少GPU Kernel的启动开销和对全局内存(HBM)的读写次数,将中间数据保留在高速的SRAM中完成计算,从而提升计算效率和内存带宽利用率。
- 典型代表:FlashAttention。它通过Tiling技术,将巨大的Attention矩阵分块,在SRAM中完成计算,避免了对整个中间结果矩阵的读写,极大加速了Attention层的计算。
- 技术:将多个独立的计算算子(如
高性能加速库 (High-Performance Libraries)
- 技术:使用如NVIDIA的FasterTransformer、TensorRT-LLM等专用库。这些库内置了高度优化的算子实现,并支持自动的算子融合和模型图优化。
- 价值:为开发者提供了开箱即用的高性能推理引擎,能够自动应用最佳的并行策略(如张量并行)和硬件加速。
3.2 算法层优化 (Algorithm-Level)
量化 (Quantization)
- 技术:使用更低的数据精度(如INT8, INT4)来表示模型的权重和/或激活值,替代传统的FP16/BF16。
- 价值:减少模型显存占用:模型体积更小,可以在单卡上部署更大的模型。加速计算:低精度计算通常比高精度计算更快。降低内存带宽需求:数据传输量减小。
- 典型代表:SmoothQuant, AWQ, GPTQ等先进的量化感知训练或训练后量化技术,旨在在降低精度的同时,最大限度地保持模型精度。

投机解码 (Speculative Decoding)
- 技术:使用一个计算开销小得多的“草稿模型”来一次性预测多个未来token,然后用原始的大模型一次性验证这些预测的token。
- 价值:将原本逐个token生成的自回归过程,变为一次性验证多个token的并行过程,从而显著减少生成每个token所需的平均延迟。
3.3 框架层优化 (Framework-Level)
连续批处理 (Continuous Batching / In-flight Batching)
- 技术:与传统的静态批处理(必须等待批次中所有请求都完成后才能开始新批次)不同,连续批处理允许在批次仍在处理时,动态地将新的请求插入进来。
- 价值:消除了因请求长度不一而导致的GPU空闲时间,将GPU利用率从30-40%提升至80%以上,从而将系统吞吐量提升2-4倍。
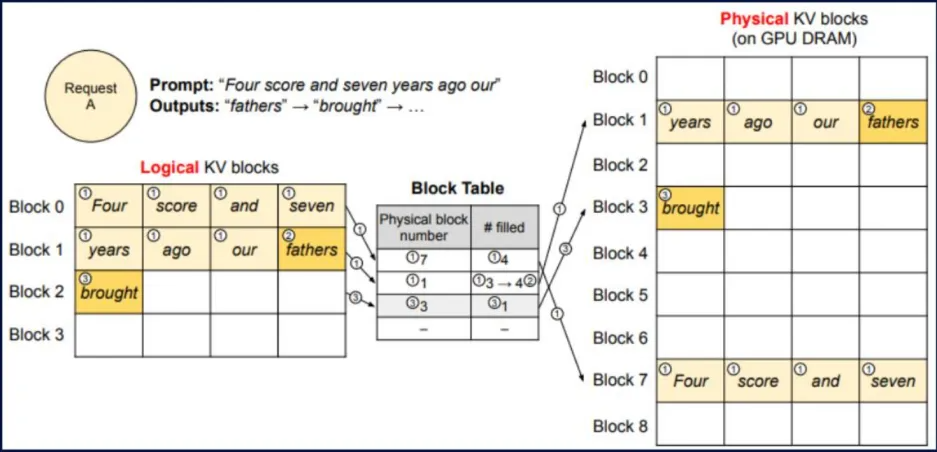
PagedAttention
- 技术:借鉴操作系统中虚拟内存和分页的思想来管理KV Cache。它将KV Cache分割成固定大小的“块”(Block),逻辑上连续的KV序列可以映射到物理上不连续的块中。
- 价值:消除内存碎片:极大提高了显存的利用效率。简化内存管理:使得KV Cache的共享和复制变得高效,是实现复杂采样算法(如Beam Search)和请求间资源共享的基础。
Prefill/Decode分离 (Split-Phase Execution)
- 技术:将计算密集但只执行一次的Prefill阶段和访存密集但需要多次迭代的Decode阶段,调度到不同的硬件或以不同的策略执行。
- 价值:允许为两个阶段分别进行资源优化和调度,例如,可以用一个大的计算集群专门处理Prefill,用另一个IO优化的集群处理Decode,从而提高整个系统的效率。
四、 核心差异对比表
| 特性 | 模型训练 (Training) | 模型推理 (Inference) |
|---|---|---|
| 主要目标 | 缩短总训练时间 (Time-to-Train) | 低延迟 (Low Latency) & 高吞吐 (High Throughput) |
| 工作负载 | 单一、长期、计算密集型的大任务 | 海量、独立、短小、I/O敏感的并发请求 |
| 集群角色 | 一台统一的、强大的**“超级计算机”** | 一个分布式的、高可用的**“服务中心”** |
| 关键技术 | 数据/模型并行、All-Reduce、梯度同步 | 负载均衡、实例复制、动态批处理、模型并行、全栈优化 |
| 网络要求 | 极致的低延迟和高带宽 (对All-Reduce至关重要) | 带宽依然重要,但更侧重于处理大量并发连接 |
| 衡量指标 | 训练吞吐量 (samples/sec)、扩展效率 | 每秒查询数 (QPS)、单次请求延迟 (ms)、首token延迟 |
五、 总结与展望
大模型推理加速是一个涉及算子、算法、框架、资源调度、底层芯片等全栈综合能力的系统工程。其核心在于提升硬件资源利用率,通过减少计算量、减少通信和内存开销,从而在满足服务质量(SLA)的前提下,降低成本。
未来,推理优化的方向将继续向更极致的效率探索:
- 更少的计算:探索更激进的压缩和量化算法(如2-bit/4-bit),甚至改变Transformer模块以降低计算复杂度。
- 硬件专用设计:为Prefill和Decode阶段设计专用的硬件模块,以应对它们截然不同的计算/访存特性。
- 异构与混合计算:更智能地利用CPU、GPU及专用加速器(如FPGA、TPU)构建混合计算平台,将不同任务分配给最适合的硬件。
- 智能调度:利用AI技术动态预测请求的计算需求,并实时调整资源分配,以实现全局最优的延迟和吞吐量。