Amazon DynamoDB生产环境数据模型无停机演进策略
Amazon DynamoDB生产环境数据模型无停机演进策略
摘要
软件应用的生命周期中,数据模型的演进是不可避免的一环。Amazon DynamoDB作为一种 schemaless(无模式)数据库,仅要求在建表时定义主键,为数据模型的迭代提供了极大的灵活性。本文旨在提供一套在生产环境中对DynamoDB数据模型进行无停机演进的策略与最佳实践。文中将重点探讨两种核心演进技术:为现有项目添加新属性以支持新访问模式,以及在单表中安全地引入新实体类型。通过具体的案例、代码实现和对事务性操作的强调,本指南将展示如何在保障服务连续性的前提下,使数据模型与时俱进,满足不断变化的业务需求。
1. 背景:在线数据模型演进的必要性与挑战
随着应用功能的迭代和业务逻辑的深化,其底层数据存储需能适应新的需求。DynamoDB的灵活性允许在表中存储结构各异的数据项,这为数据模型的演进奠定了基础。然而,当演进涉及为已有数据添加新属性,或引入全新的访问模式时,就必须面对一系列挑战,尤其是在一个持续提供服务的生产环境中。
核心挑战在于:如何在不中断服务(零停机)的前提下,完成对存量数据的模型变更,并确保在过渡期间,新旧数据结构共存时系统的稳定与数据的一致性。
2. 核心概念解析
在深入探讨演进策略之前,有必要对文档中涉及的几个DynamoDB核心概念进行说明。
全局二级索引 (Global Secondary Index, GSI) GSI是DynamoDB提供的一种强大的功能,它允许对同一个表的数据创建一套不同于主键的、全新的键结构,从而支持多样化的查询模式。可以将其理解为对主表数据的一个“物化视图”。GSI拥有自己的分区键和可选的排序键,并独立于主表进行吞吐量配置。当主表数据发生变更时,包含GSI键和投射属性的数据会以最终一致的方式异步复制到GSI中。
实体 (Entity) 与单表设计 (Single-Table Design) 在DynamoDB的最佳实践中,通常推荐使用“单表设计模式”,即在一个表中存储应用中所有不同类型的业务对象。在此模式下,一个**“实体”**指的是一个逻辑上的业务对象,例如一个“订单(Order)”、一个“顾客(Customer)”或一个“商品(Product)”,尽管它们都以数据项(Item)的形式存储在同一张物理表中。为了区分和关联不同的实体,通常会使用通用的主键名(如
PK,SK),并通过在键值中嵌入实体类型前缀(如PK: CUST#123,SK: ORDER#456)来实现。表与实体的具体展现形式 在单表设计中,**“表”是物理的,指代一个包含了多种不同结构数据项的单一容器。而“实体”**是逻辑的,指代一个具体的业务对象,它以表中一个数据项(Item)的形式存在。实体的类型通过其主键(尤其是排序键SK)的结构和前缀来区分。例如,在本文的
Orders表中,订单实体和收藏品实体共存于一张表中,其具体展现形式如下:CustomerId (PK) SK (排序键) Items (订单商品列表) ItemName (收藏品名称) 备注 79702414002025-03-01#2121195[...](不存在) 这是一个订单实体 7970241400FAVOURITE#484295(不存在) Eggs这是一个收藏品实体 7970241400FAVOURITE#833611(不存在) Milk这是另一个收藏品实体
3. 策略一:为现有项目添加新属性与访问模式
3.1. 场景描述
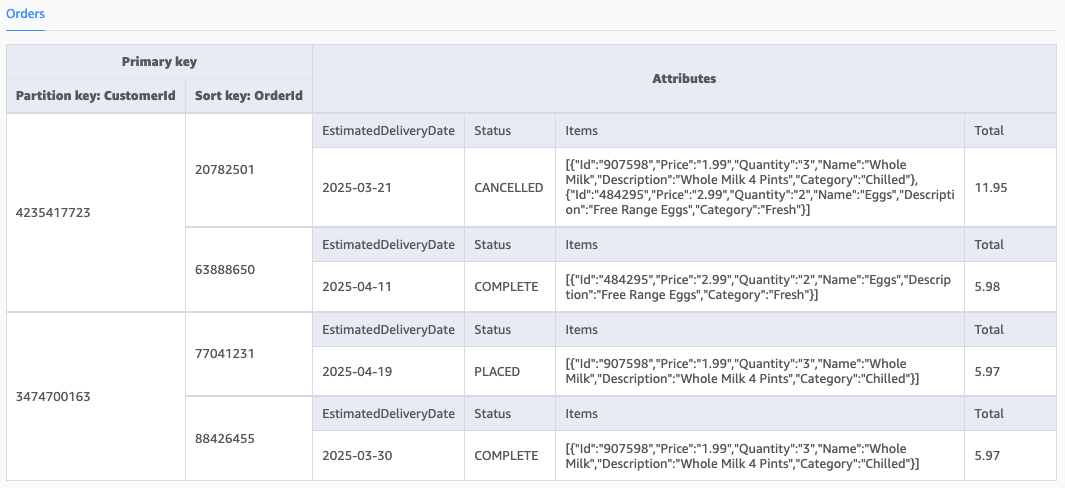
设想一个电商平台的订单表,初始设计旨在通过CustomerId和OrderId查询订单。随着业务发展,出现了一个新的需求:需要根据**配送日期(DeliveryDate)**来查询订单。这是一种全新的访问模式,原有的主键结构无法高效支持。
初始数据模型如下图所示:
3.2. 解决方案:利用全局二级索引 (GSI)
针对新增的访问模式,最优的演进策略是创建一个全局二级索引(GSI)。
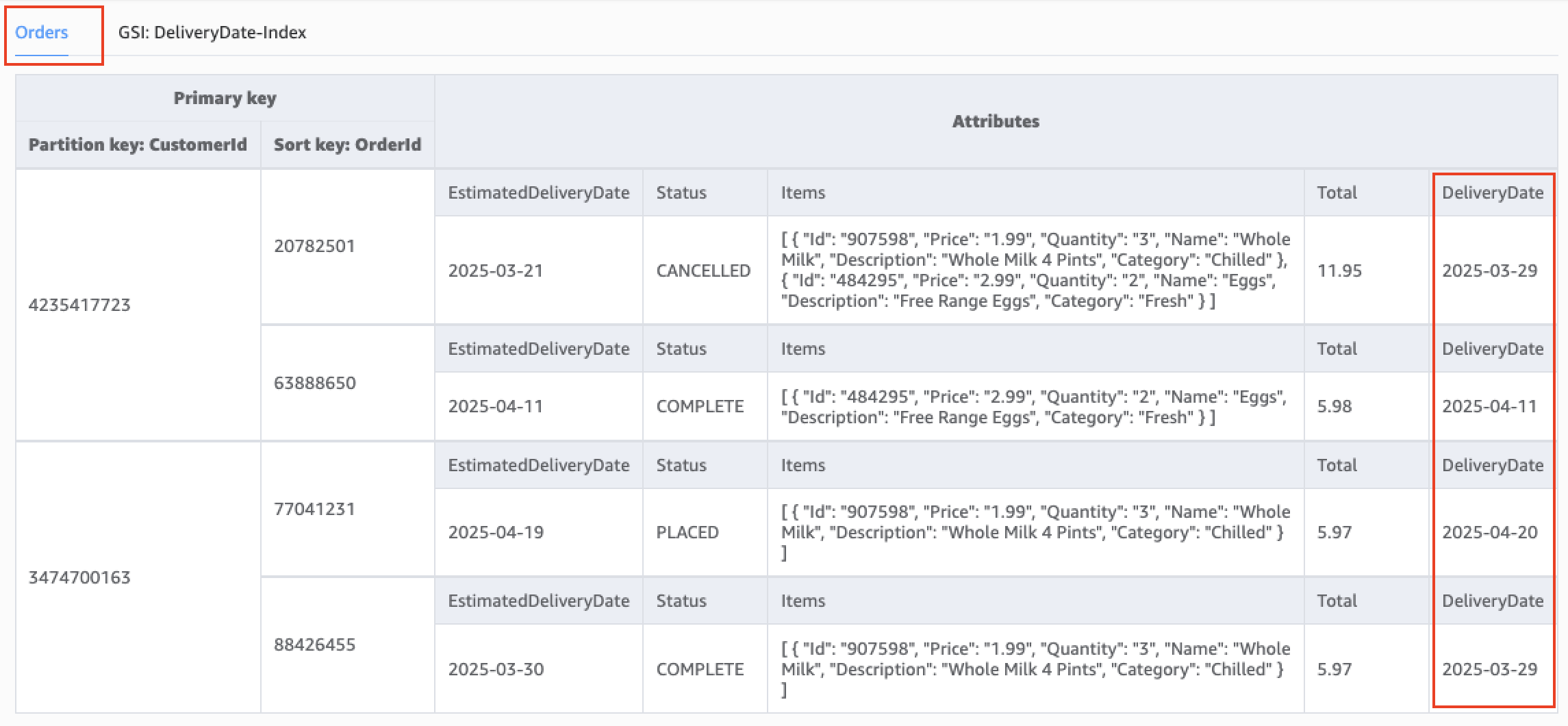
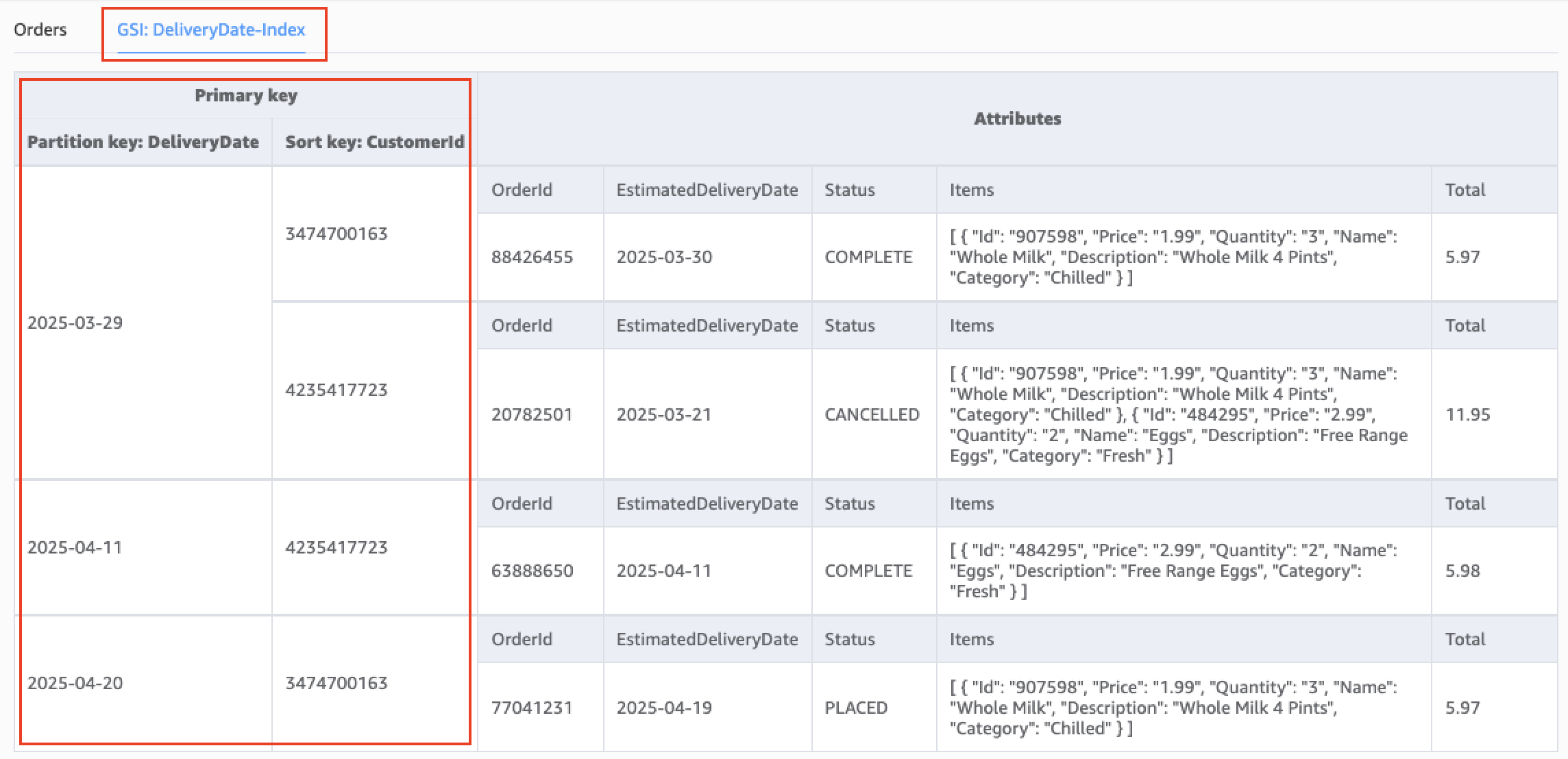
- 定义新GSI:创建一个名为
DeliveryDate-Index的GSI,其分区键设置为新属性DeliveryDate。 - 更新写入逻辑:应用程序在写入新订单或更新旧订单时,开始包含
DeliveryDate这个新属性。 - GSI的自动填充:当一个包含
DeliveryDate属性的数据项被写入主表时,DynamoDB会自动将该GSI的键以及投射属性异步复制到索引中。
演进后的数据模型与GSI结构:
3.3. 代码实现
通过查询新建的GSI,即可实现按配送日期检索订单的功能。
try:
# 通过新创建的GSI,按配送日期查询订单
response = client.query(
# 主表名称
TableName='Orders',
# 指定要查询的GSI名称
IndexName='DeliveryDate-index',
# 定义查询条件:分区键DeliveryDate等于指定值
KeyConditionExpression='DeliveryDate = :delivery_date',
# 为查询条件中的占位符提供具体值
ExpressionAttributeValues={
':delivery_date': { 'S': '2025-03-21' }
}
)
return response
except Exception as e:
print(f"查询时发生错误: {str(e)}")
return []
3.4. 历史数据迁移考量
对于不含DeliveryDate的存量订单数据,存在两种处理策略的权衡:
- 渐进式更新:修改应用逻辑,使其能够兼容缺少
DeliveryDate属性的旧数据。同时,当旧数据被访问时,顺便为其补上该属性。 - 批量更新:通过AWS Step Functions或AWS Glue等服务,编写一次性脚本,扫描全表并为所有存量订单数据补上
DeliveryDate属性。
4. 策略二:在单表中添加新实体类型
4.1. 场景描述
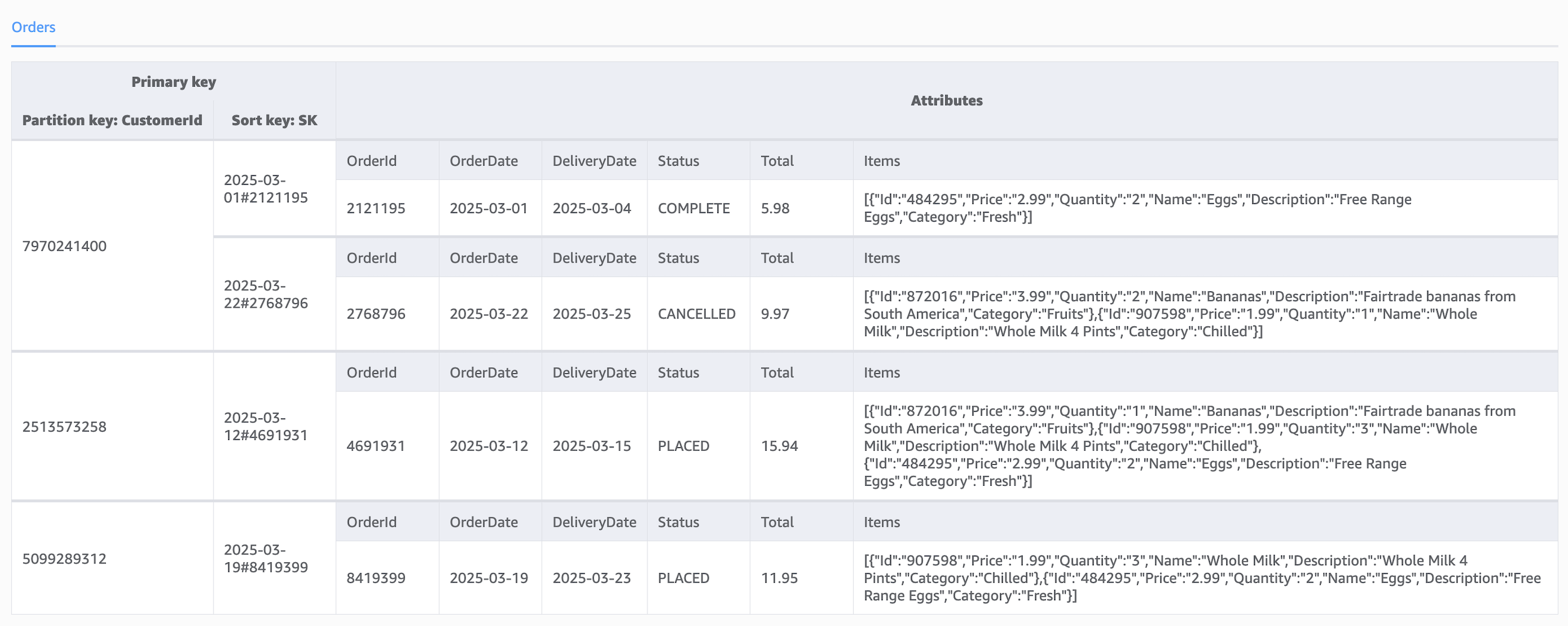
在单表设计模式下,一个DynamoDB表可以存储多种不同类型的实体。现需为上述订单系统增加一个“收藏商品”的功能。这需要在订单数据之外,引入一个全新的**“收藏品(Favourite Item)”**实体。
初始数据模型(使用复合排序键):
4.2. 解决方案:利用复合主键与前缀查询
- 扩展现有实体:在
Order实体的Items列表中,为每个商品增加一个布尔类型的Favourite嵌套属性。 - 定义新实体:在同一个表中,定义
Favourite Item这个新实体。其主键结构经过精心设计:- 分区键 (PK):与
Order实体保持一致,使用CustomerId。 - 排序键 (SK):使用一个固定的前缀加上商品ID,例如
FAVOURITE#<ItemId>。
- 分区键 (PK):与
- 实现高效查询:通过使用
begins_with操作符查询排序键,可以高效地获取某位顾客的所有收藏商品。
演进后的数据模型(包含两种实体):
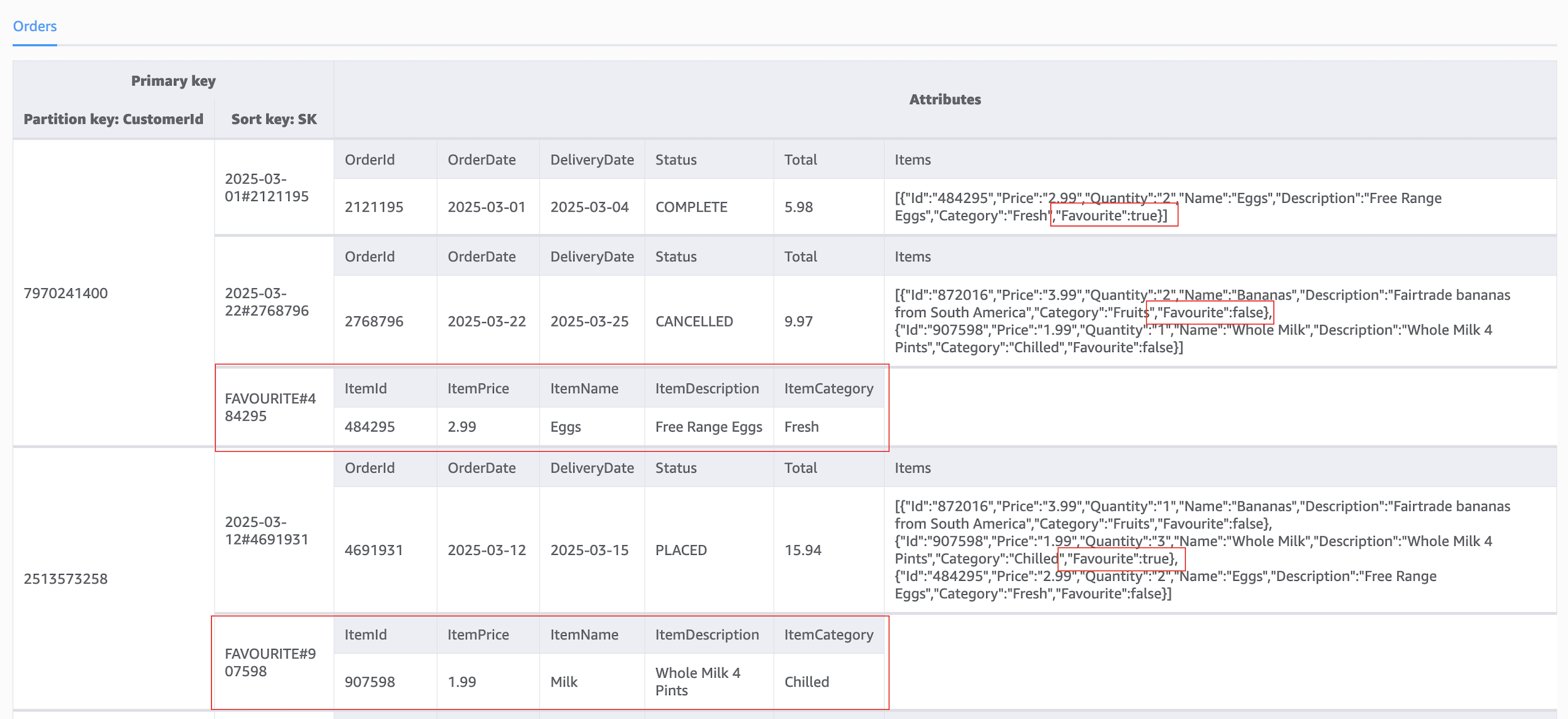
4.3. 代码实现
以下代码展示了如何查询某位顾客的所有收藏商品。
try:
# 查询某位顾客的所有收藏商品
response = client.query(
TableName='Orders',
# 查询条件:PK等于指定CustomerId,且SK以'FAVOURITE#'开头
KeyConditionExpression='CustomerId = :customer_id AND begins_with(SK, :sk)',
# 为查询条件中的占位符提供具体值
ExpressionAttributeValues={
':customer_id': { 'S': '7970241400' },
':sk': { 'S': 'FAVOURITE#' }
}
)
return response
except Exception as e:
print(f"查询时发生错误: {str(e)}")
return []
5. 演进过程中的最佳实践与数据一致性保障
5.1. 在应用层保障数据完整性
DynamoDB本身不维护表内不同实体间的关系(即没有外键约束)。因此,保障数据一致性和完整性的责任需要由应用层来承担。推荐在执行涉及多个关联实体的操作时,使用事务(Transactions)和条件写入(Conditional Writes)。
例如,当用户将订单中的某个商品加为收藏时,这个单一操作需要原子性地完成两件事:1) 创建一个新的Favourite Item实体;2) 更新原Order实体中对应商品的Favourite标记。使用TransactWriteItems可以确保这两个操作要么全部成功,要么全部失败,从而避免数据不一致。
try:
# 执行一个事务性写入操作,确保数据一致性
response = client.transact_write_items(
TransactItems=[
# 操作1: 创建一个新的“收藏品”实体 (Put操作)
{
'Put': {
'TableName': 'Orders',
'Item': {
'CustomerId': { 'S': '7970241400' },
'SK': { 'S': 'FAVOURITE#484295' },
'ItemId': { 'S': '484295' },
'ItemPrice': { 'S': '2.99' },
'ItemName': { 'S': 'Eggs' },
'ItemDescription': { 'S': 'Free Range Eggs' },
'ItemCategory': { 'S': 'Fresh' }
}
}
},
# 操作2: 更新对应订单中,该商品项目的Favourite标记 (Update操作)
{
'Update': {
'TableName': 'Orders',
# 定位到要更新的具体订单项
'Key': {
'CustomerId': { 'S': '7970241400' },
'SK': { 'S': '2025-03-01#2121195' }
},
# 更新表达式:设置Items列表中第一个元素的Favourite属性为True
'UpdateExpression': 'SET #Items[0].Favourite = :Favourite',
# 定义表达式中的属性名占位符,避免与保留关键字冲突
'ExpressionAttributeNames': {
'#Items': 'Items'
},
# 定义表达式中的属性值占位符
'ExpressionAttributeValues': {
':Favourite': { 'BOOL': True },
':ItemId': { 'S': '484295' }
},
# 条件表达式:确保正在更新的确实是目标商品,防止并发修改导致错误
'ConditionExpression': '#Items[0].Id = :ItemId'
}
}
]
)
return response
except Exception as e:
print(f"事务写入时发生错误: {e}")
return []
5.2. 其他最佳实践
- GSI投射与成本优化:创建GSI时,仅投射查询所必需的属性(
KEYS_ONLY或INCLUDE),以显著降低存储和写入成本。 - 演进文档化:对数据模型的任何变更都应进行详尽的文档记录。
- 避免在DynamoDB中进行分析型查询:对于OLAP需求,应利用其与Amazon OpenSearch Service, Redshift, S3等的零ETL集成能力。
- 最小化索引数量:力求用最少的索引满足所有访问模式,以优化成本。
6. 总结
DynamoDB的 schemaless 特性为数据模型演进提供了基础,但安全、无缝地在生产环境中完成演进,则需要一套严谨的策略。通过合理运用全局二级索引(GSI)来支持新的访问模式,利用带有前缀的排序键在单表中添加新实体,并借助事务来保障跨项操作的原子性,可以实现复杂数据模型的零停机演进。在整个过程中,周全的规划、详尽的文档以及对成本与性能的权衡是确保成功的关键。