高并发一致性分布式计数器架构扩展实践演进:设计每秒十万请求量级的视图计数系统
高并发一致性分布式计数器架构扩展实践演进:设计每秒十万请求量级的视图计数系统
摘要
本文旨在深入探讨如何设计一个能够应对海量请求(例如,超过10万RPS)的分布式视频视图计数系统。我们将从一个基础的架构方案入手,逐步分析其在可扩展性、性能和数据一致性等方面遇到的瓶颈与挑战。通过四次架构迭代——从单体数据库到分片数据库,再到内存聚合,最终演进至基于事件驱动的流处理架构——我们将系统性地展示如何解决高并发写入、热点分区、数据持久化和幂等性等关键问题。本文不仅提供了具体的技术选型(如Kafka、Flink、Redis)和设计权衡,还总结了一套通用的分布式系统设计方法论,为构建其他大规模计数应用(如广告点击、社交媒体点赞等)提供参考。
1. 核心性能指标解析 (RPS, QPS, PV, UV)
在深入架构设计之前,我们首先需要明确衡量系统负载和用户活动的核心指标,这对于理解我们的设计目标至关重要。
产品和运营更加关注UV和PV;技术和运维更加关注RPS和QPS。
UV (Unique Visitor - 独立访客数)
- 视角: 用户客户端。
- 含义: 在特定时间段内(通常是一天)访问网站的独立用户数量。无论一个用户当天访问多少次,都只被记为一个UV。这是衡量产品覆盖范围和真实用户规模的核心指标。
PV (Page View - 页面浏览量)
- 视角: 用户客户端。
- 含义: 网站或应用中某个页面被加载或刷新的总次数。一个UV可以产生多个PV,该指标反映了用户的活跃度和内容的受欢迎程度。
RPS (Requests Per Second - 每秒请求数)
- 视角: 应用服务器端。
- 含义: 应用服务器每秒钟实际处理的请求总数。一个PV通常会触发多个RPS(如HTML、API、图片等请求)。RPS直接反映了服务器的处理能力和当前负载,是容量规划和性能压测的关键指标。
QPS (Queries Per Second - 每秒查询数)
- 视角: 后端服务(如数据库)。
- 含义: 特指对某个后端服务(尤其是数据库)的每秒查询次数。一个RPS请求可能会导致多个QPS。例如,一个API请求(1 RPS)可能需要查询3次数据库(3 QPS)。QPS是衡量后端服务负载压力的关键指标。
关系链: 一个UV -> 访问了多个PV -> 触发了海量的RPS -> 导致了更多的QPS。
2. 引言
2.1 问题背景
某流媒体应用的热门视频拥有数百亿的播放量,这一数字的背后是一个高并发、高可用的分布式计数系统。表面上看,实现视图计数似乎只是简单的累加操作,但当系统需要处理每日数十亿次的观看请求,并应对“病毒式”传播视频带来的流量洪峰时,问题的复杂性便显现出来。如何在保证数据精确性的同时,满足系统的可扩展性和性能要求,是每个大型内容平台都必须解决的核心技术挑战。
2.2 本文目标
本文将从零开始,设计一个完整的视频视图计数系统。我们将遵循以下演进路径:
优秀的架构实践要遵循:1)适配业务和团队技术能力的当前现状;2)架构具备向前演进性和向后兼容性;3)架构的过程设计文档要规范专业;
- 定义问题:明确系统的功能性与非功能性需求。
- 基础方案:提出一个最简单的实现方案,并分析其局限性。
- 架构迭代:通过多次迭代,逐步优化架构,解决扩展性、性能、数据一致性等问题。
- 最终方案:构建一个基于事件驱动和流处理的、满足所有需求的健壮系统。
通过本文,读者将掌握设计大规模分布式计数系统的核心原则与权衡策略,提升系统设计能力。
3. 需求分析
3.1 功能性需求 (Functional Requirements)
- FR-1: 追踪视频观看:系统必须能够记录用户对视频的每一次有效观看行为。
- FR-2: 展示视频观看次数:在视频播放页面,系统需要向用户展示当前的观看总数。
3.2 非功能性需求 (Non-Functional Requirements)
3.2.1 针对追踪视频观看 (FR-1)
- 可扩展性 (Scalability):系统需支持3亿日活用户规模,并能应对因“病毒式”视频引发的突发性流量高峰。
- 幂等性 (Idempotency):系统必须避免重复计数。即使用户多次刷新页面,同一次观看行为也只能被记为一次。
- 性能 (Performance):计数功能的引入不应影响现有视频播放服务的性能。
3.2.2 针对展示视频观看次数 (FR-2)
- 性能 (Performance):在视频播放期间,获取观看次数的延迟应在 200毫秒 以内。
- 最终一致性 (Eventual Accuracy):观看次数必须保证100%准确,但允许存在一定的延迟(例如,小于10分钟)。
- 可用性 (Availability): 展示观看次数的服务需要达到 99.99% 的服务等级协议(SLA)。
4. 实体、参与者及API设计
4.1 核心实体与参与者
- 用户 (Users): 观看视频并查看观看次数的终端用户。
- 视频 (Videos): 每个视频关联一个观看计数值。
Java伪代码示例
// 代表用户的实体
public class User {
private String userId;
private String name;
// ... 其他用户属性
}
// 代表视频的实体
public class Video {
private String videoId;
private String title;
// ... 其他视频属性
}
// 代表视频观看次数的实体,通常用于数据库存储
public class VideoView {
private String videoId;
private long viewCount;
}
4.2 API 接口设计
API Endpoint的设计遵循了业界广泛认可的RESTful风格,这是一种成熟的、可扩展的Web服务设计规范。具体体现在:
- 版本化管理: 路径中包含版本号(如
/v1),确保了API的向后兼容性。当未来API发生重大变更时,可以通过递增版本号(如/v2)来发布新版API,而不会影响现有客户端的集成。 - 资源导向: URL路径清晰地指向了操作的资源。例如,
videos代表视频资源集合,views代表观看次数这一子资源。这种设计直观且易于理解。 - 使用HTTP动词: 通过HTTP方法(
POST、GET)来定义对资源的操作类型。POST用于创建新资源(或在本例中,提交一个事件),GET用于检索资源,这符合HTTP协议的标准用法。 - 路径参数: 使用路径参数(如
{videoId})来唯一标识和定位单个资源,使得API调用更加精确。
4.2.1 追踪视频观看 API (FR-1)
- Endpoint:
POST /v1/views - Request Body:
{ "videoId": "string", "userId": "string", "timestamp": "datetime" } - Response:
202 Accepted(表示请求已被接收,将异步处理)
4.2.2 展示视频观看次数 API (FR-2)
- Endpoint:
GET /v1/videos/{videoId}/views - Path Parameter:
videoId: 视频的唯一标识符。
- Response Body:
{ "videoId": "string", "viewCount": "integer" }
4.3 高层设计
系统包含两条核心数据流:
- 写入路径 (Write Path): 捕获用户观看事件,并增加计数值。
- 读取路径 (Read Path): 获取并向用户展示计数值。
由于每次观看都伴随着一次展示,系统的读写比约为 1:1。

5. 架构演进
5.1 方案一:单体关系型数据库
最直接的方案是使用一个服务和一个关系型数据库(如 PostgreSQL 或 MySQL)。数据库中包含一张 VideoViews 表,用于存储每个视频的计数值。
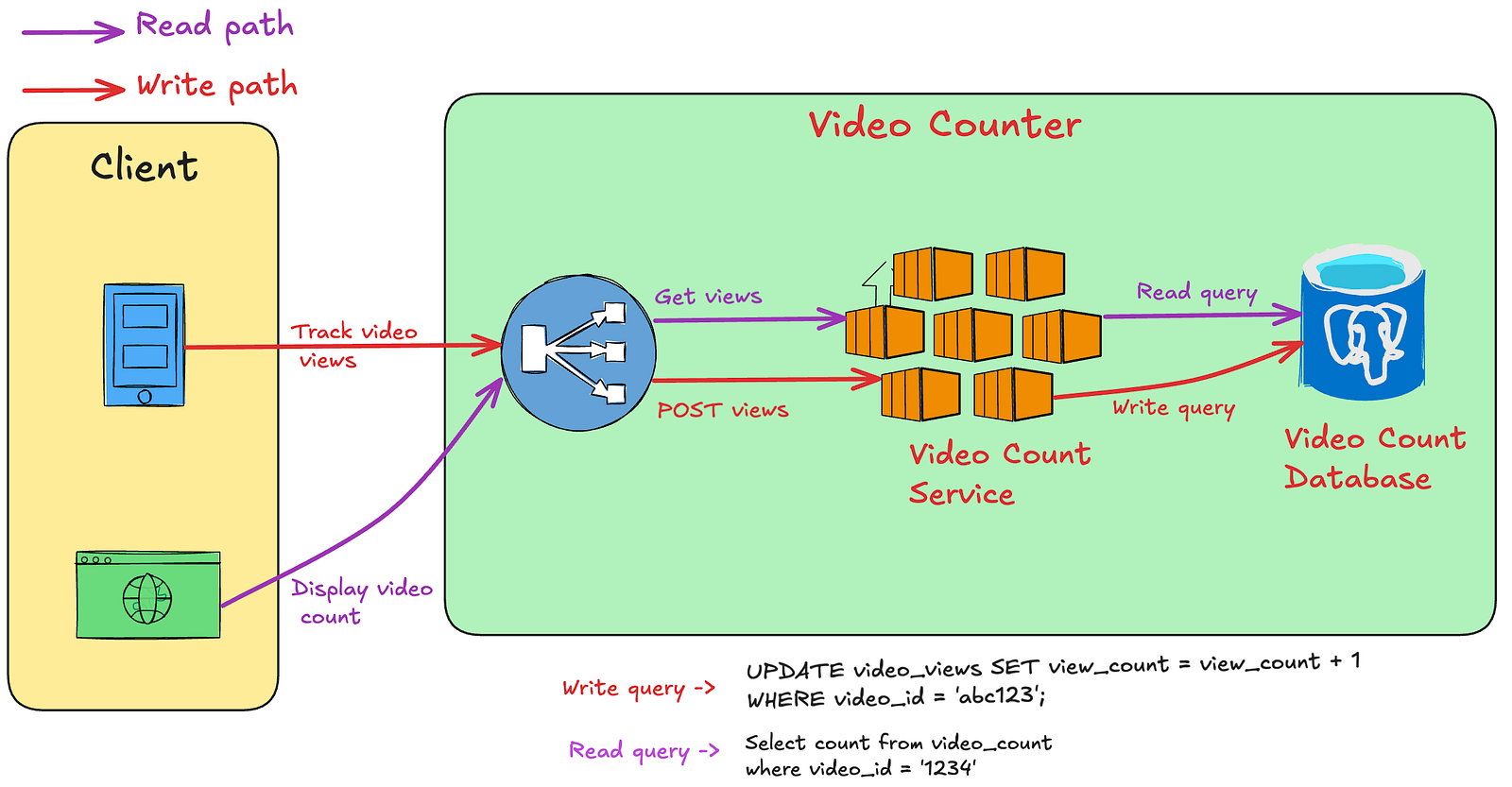
Java伪代码示例
// Warning: This code is NOT thread-safe and has race conditions.
@Service
public class ViewCounterServiceV1 {
// 在实际项目中,我们通常使用依赖注入(DI)来管理组件。
// @Autowired是Spring框架中实现DI的一种方式。
// 但在伪代码中,为了保持简洁和框架无关性,我们省略它,
// 并假设repository实例已通过某种方式(如构造函数)注入。
private VideoViewRepository repository;
@Transactional
public void incrementViewCount(String videoId) {
// 1. Read the current count from the database.
VideoView view = repository.findById(videoId).orElse(new VideoView(videoId, 0L));
// 2. Increment the count in memory.
view.setViewCount(view.getViewCount() + 1);
// 3. Write the new count back to the database.
repository.save(view);
}
}
瓶颈分析:
假设日活用户为2亿,每人每天观看5个视频,则日均请求量为10亿次。换算成每秒请求数(RPS):
平均RPS = 10亿 / 86400秒 ≈ 10,000 RPS
考虑到流量高峰,峰值RPS可能达到 5万至10万。单体关系型数据库无法承受如此高的写入吞吐量,会导致以下问题:
- 单点故障 (Single Point of Failure): 数据库宕机将导致整个服务不可用。
- 吞吐量瓶颈: 数据库性能达到上限,请求大量失败,影响可用性和数据准确性。
- 性能下降: 请求处理延迟远超200毫秒的目标。
- 缺乏幂等性: 简单的
UPDATE ... SET count = count + 1操作无法处理重复请求。
注:即使换成非关系型数据库,单个实例的吞吐量上限问题依然存在。
5.2 方案二:数据库分片 (Sharding)
为了解决单实例的吞吐量瓶颈,我们可以将数据分片到多个数据库实例上。例如,使用10个数据库实例,每个实例处理1万RPS的流量。
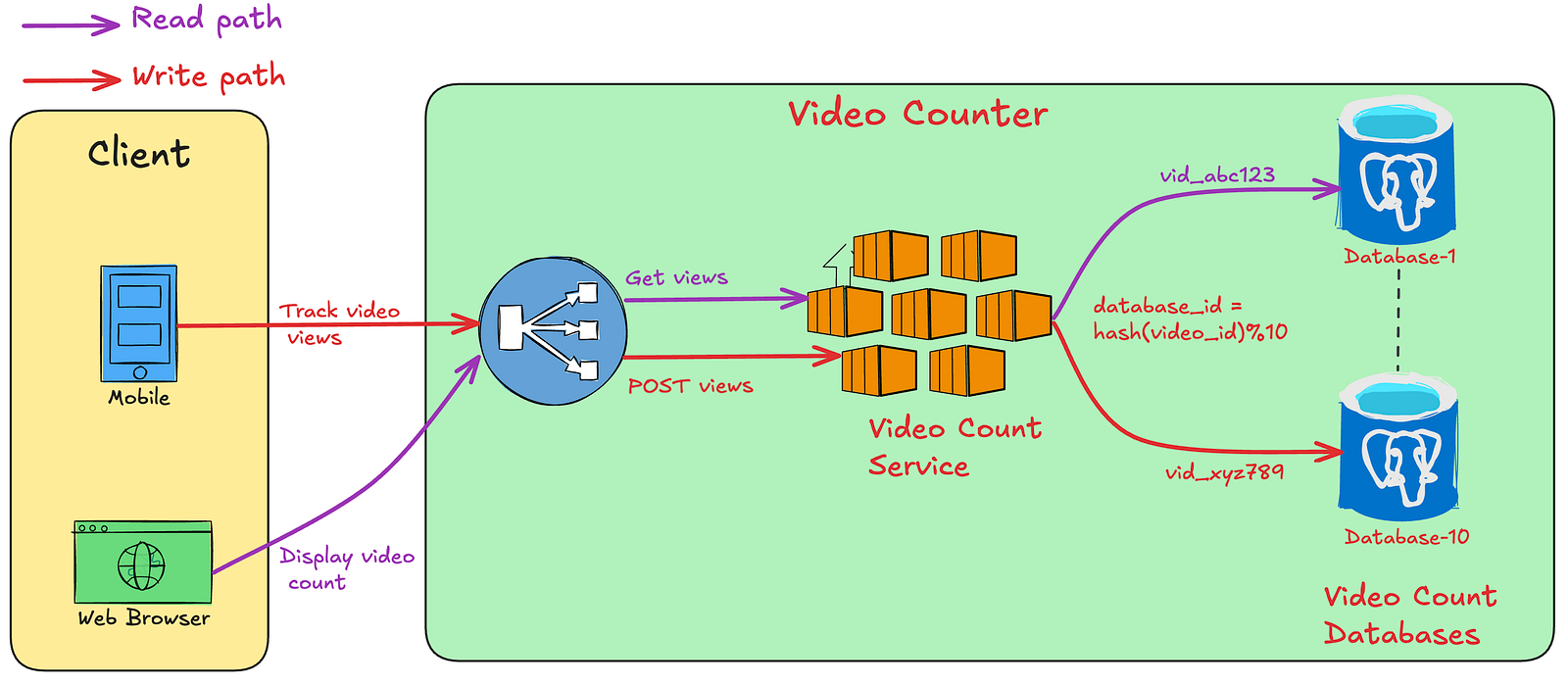
瓶颈分析:
该方案虽然提升了整体吞吐量,但引入了新的问题:
- 热点分区问题 (Hot Partition Problem): 当某个视频突然爆火(成为“病毒式”视频),所有针对该视频的读写请求都会集中到单一的分片上,导致该分片过载,而其他分片资源闲置。
一种改进方法是将热点视频的数据分散到多个分片上,由服务层进行请求分发和结果聚合。但这会增加读取路径的复杂性和延迟,因为需要从多个分片查询数据并汇总。
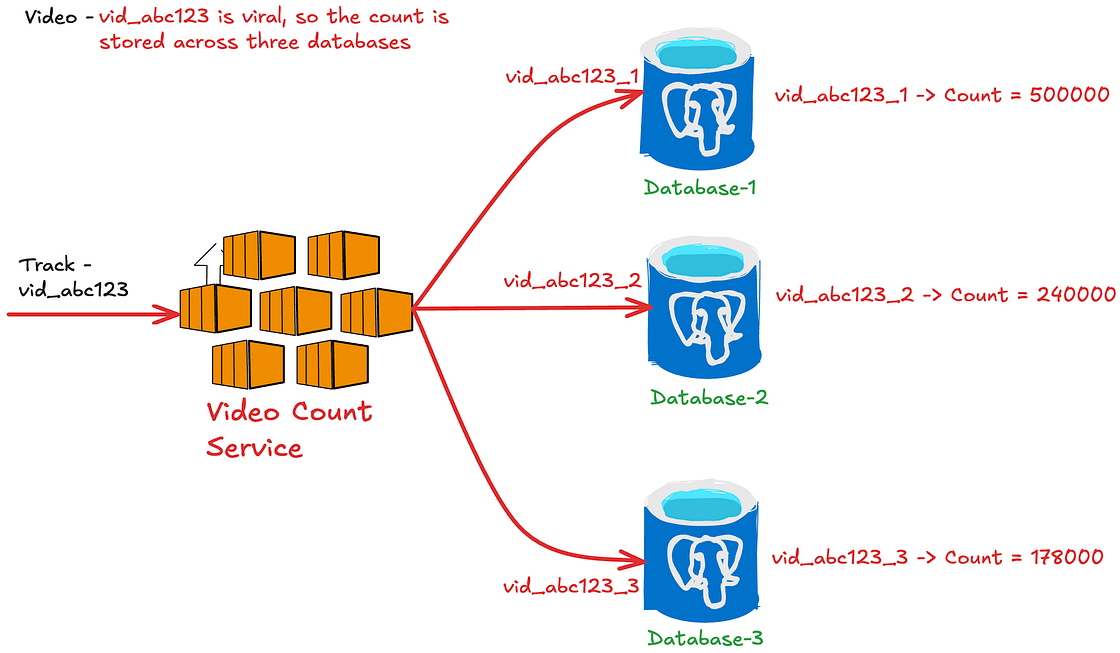
此外,幂等性问题仍未解决。
5.3 方案三:内存聚合与持久化
前两种方案的核心问题是每次请求都直接操作数据库,导致写入压力巨大。我们可以引入内存计算来优化此过程。
设计思路:
幂等性保证: 引入缓存(如 Redis)来存储幂等键(Idempotency Key)。幂等键可由
videoId和userId等信息组合生成,并设置一个时间窗口(如1小时)的TTL。服务在接收到请求时,首先检查缓存中是否存在该键,若存在则直接丢弃,实现去重。内存聚合: 服务实例在内存中对观看次数进行聚合,而不是立即写入数据库。例如,每隔10分钟,将内存中的计数值批量更新到数据库中。
缓存读取: 读取路径优先从缓存中获取计数值。若缓存未命中,则从数据库加载,并回填缓存。缓存のTTL与批量更新周期保持一致(10分钟),满足最终一致性的要求。
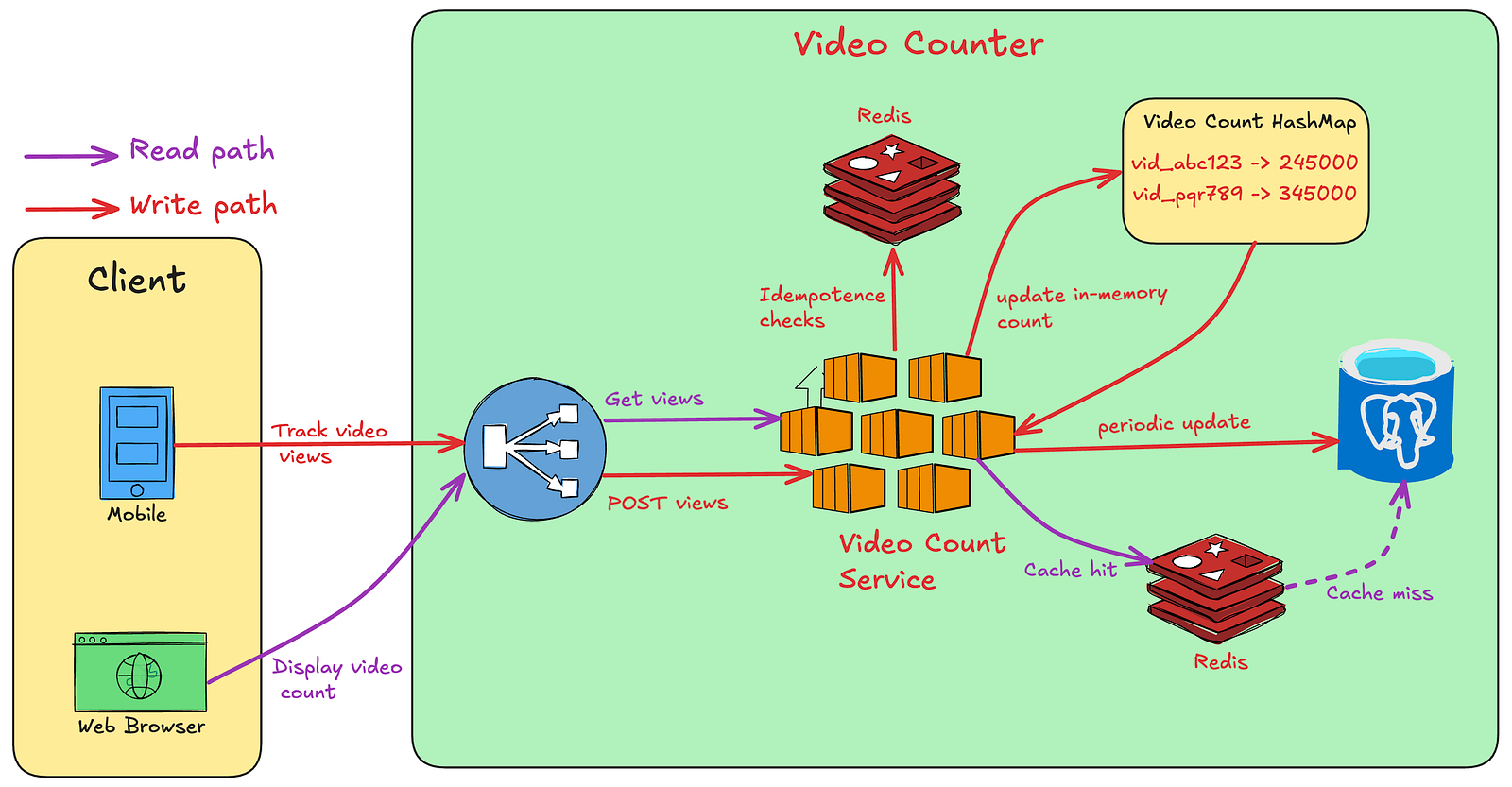
Java伪代码示例
@Service
public class ViewCounterServiceV3 {
// 在实际项目中,我们通常使用依赖注入(DI)来管理组件。
// @Autowired是Spring框架中实现DI的一种方式。
// 但在伪代码中,为了保持简洁和框架无关性,我们省略它,
// 并假设redisTemplate实例已通过某种方式(如构造函数)注入。
private RedisTemplate<String, String> redisTemplate;
private final ConcurrentMap<String, AtomicLong> localCounter = new ConcurrentHashMap<>();
public void processViewEvent(String videoId, String userId) {
// 1. 生成幂等键
String idempotencyKey = "view:" + videoId + ":" + userId;
// 2. 使用Redis的SETNX命令检查键是否存在,如果不存在则设置并返回true
Boolean isFirstView = redisTemplate.opsForValue().setIfAbsent(idempotencyKey, "1", Duration.ofHours(1));
// 3. 如果是第一次观看,则在本地内存中增加计数
if (Boolean.TRUE.equals(isFirstView)) {
localCounter.computeIfAbsent(videoId, k -> new AtomicLong(0)).incrementAndGet();
}
}
// 4. 使用@Scheduled注解,定时将内存中的计数值持久化到数据库
@Scheduled(fixedRate = 10 * 60 * 1000) // 每10分钟执行一次
public void persistCountersToDB() {
// 创建一个当前计数的快照并清空内存计数器
Map<String, AtomicLong> snapshot = new HashMap<>(localCounter);
localCounter.clear();
// 批量更新数据库
// database.batchUpdateCounts(snapshot);
System.out.println("Persisting to DB: " + snapshot);
}
}
瓶颈分析:
该方案显著降低了数据库的写入负载,并解决了幂等性问题。但其致命弱点在于:
- 数据丢失风险: 由于计数值在内存中聚合,如果服务实例在持久化之前崩溃,这部分数据将永久丢失,导致计数不准确。
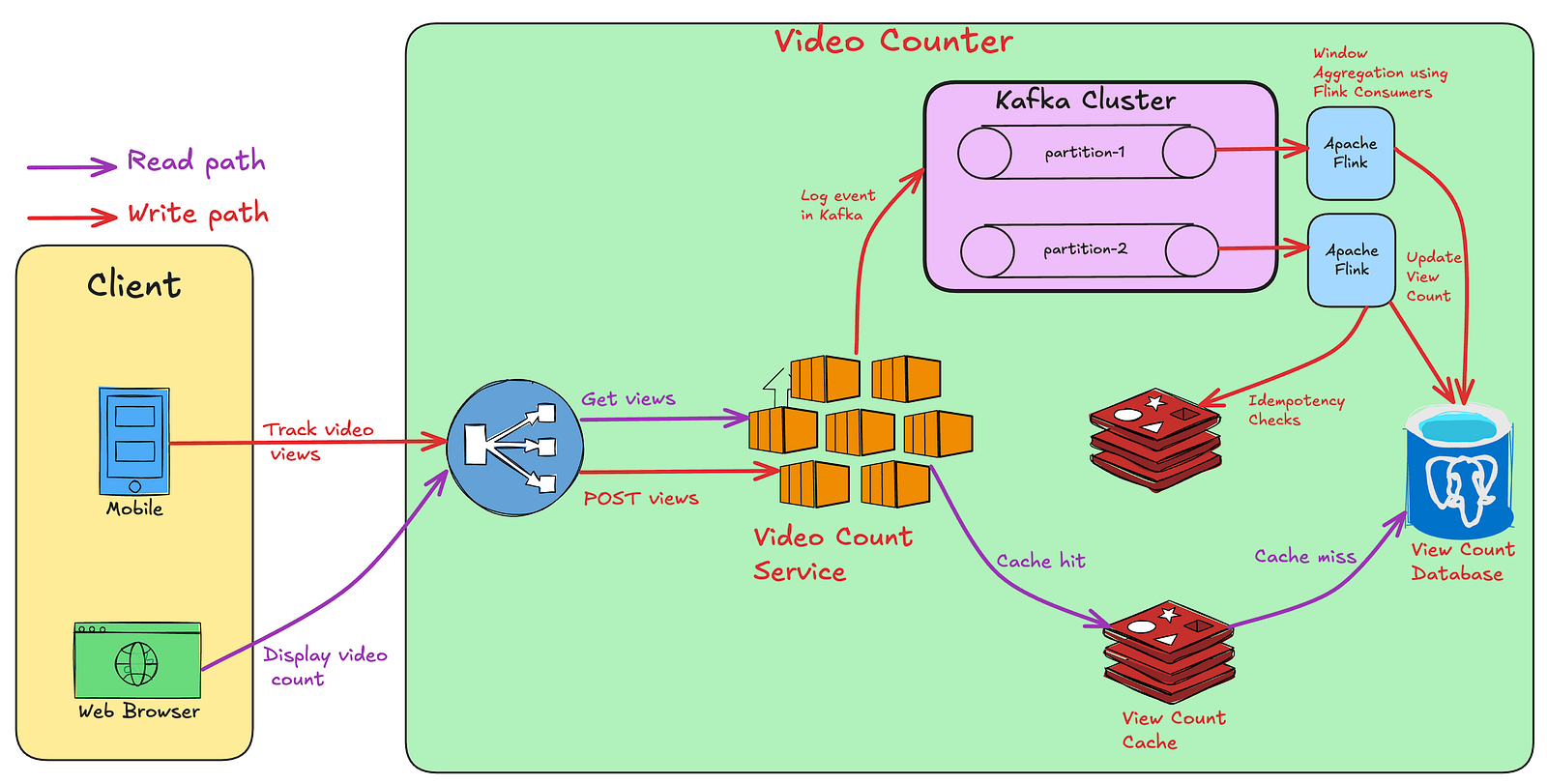
5.4 方案四:基于事件驱动的流处理架构
为了解决数据持久性和高吞吐写入的问题,我们引入事件驱动架构。
核心组件:
- 消息队列 (Message Queue): 使用 Apache Kafka 作为事件总线。Kafka 支持高吞吐、低延迟的写入,并提供数据持久化保证。
- 流处理平台 (Stream Processing): 使用 Apache Flink 对 Kafka 中的事件流进行实时处理。
架构流程:
- 事件发布: 视频计数服务接收到观看请求后,不再直接处理,而是将该事件(包含
videoId,userId等信息)发布到 Kafka 的一个特定主题(Topic)中。数据可以根据videoId进行分区,以保证同一视频的事件由同一个消费者处理。
Java伪代码示例 (事件发布)
@Service
public class ViewEventProducer {
// 在实际项目中,我们通常使用依赖注入(DI)来管理组件。
// @Autowired是Spring框架中实现DI的一种方式。
// 但在伪代码中,为了保持简洁和框架无关性,我们省略它,
// 并假设kafkaTemplate实例已通过某种方式(如构造函数)注入。
private KafkaTemplate<String, ViewEvent> kafkaTemplate;
private static final String TOPIC = "video-views-topic";
public void sendViewEvent(String videoId, String userId) {
ViewEvent event = new ViewEvent(videoId, userId, Instant.now());
// 使用videoId作为Key,确保同一视频的事件进入同一个Kafka分区
kafkaTemplate.send(TOPIC, videoId, event);
}
}
事件消费与处理: Flink 作业消费 Kafka 主题中的事件。Flink 在一个时间窗口内(如10分钟)对事件进行聚合和去重。
- 去重: Flink 作业内部可以利用状态存储(如 RocksDB)或外部缓存(如 Redis)来检查事件的幂等键,实现精确一次(Exactly-once)处理。
- 聚合: Flink 对窗口内的有效事件按
videoId进行计数。
数据持久化: 在每个时间窗口结束时,Flink 将聚合后的计数值批量更新到最终的数据存储(如关系型数据库或键值存储)中。
数据读取: 读取路径保持不变,依然通过缓存+数据库的方式提供服务,保证低延迟。
Flink作业伪代码逻辑
// This is a descriptive pseudocode for a Flink job
public class FlinkViewCountProcessor {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 从Kafka源读取事件流
DataStream<ViewEvent> stream = env.fromSource(kafkaSource, ...);
// 2. 按videoId进行分组
KeyedStream<ViewEvent, String> keyedStream = stream.keyBy(ViewEvent::getVideoId);
// 3. 定义10分钟的滚动时间窗口
WindowedStream<ViewEvent, String, TimeWindow> windowedStream = keyedStream
.window(TumblingProcessingTimeWindows.of(Time.minutes(10)));
// 4. 在窗口内进行去重和计数
DataStream<VideoViewCount> resultStream = windowedStream
.aggregate(new DeduplicatingAggregator()); // 自定义聚合器
// 5. 将聚合结果写入数据库
resultStream.addSink(new DatabaseSink()); // 自定义Sink
env.execute("Flink View Count Job");
}
/**
* 自定义聚合器,用于在时间窗口内对观看事件进行去重和计数。
* 它实现了AggregateFunction接口,通过内部状态(Accumulator)来跟踪每个窗口中已见过的用户ID。
* Flink的StateBackend会负责此状态的持久化和故障恢复,从而保证Exactly-Once。
*
* @param <ViewEvent> 输入事件类型
* @param <Accumulator> 中间状态类型,包含一个用于去重的Set
* @param <VideoViewCount> 输出结果类型
*/
private static class DeduplicatingAggregator
implements AggregateFunction<ViewEvent, DeduplicatingAggregator.Accumulator, VideoViewCount> {
// Accumulator是聚合过程中的状态容器。
// Flink会自动为每个窗口(按Key分组)管理这个状态。
public static class Accumulator {
public String videoId;
// 使用Set来高效地存储和查询唯一的userId。
public Set<String> distinctUsers = new HashSet<>();
}
@Override
public Accumulator createAccumulator() {
// 为每个新窗口创建一个空的累加器。
return new Accumulator();
}
@Override
public Accumulator add(ViewEvent event, Accumulator accumulator) {
// 此方法为窗口中的每个事件调用。
// 这是实现去重逻辑的核心。
if (accumulator.videoId == null) {
accumulator.videoId = event.getVideoId();
}
// Set.add()方法只有在元素不存在时才会添加并返回true。
// 我们利用这个特性来自然地实现去重。
accumulator.distinctUsers.add(event.getUserId());
return accumulator;
}
@Override
public VideoViewCount getResult(Accumulator accumulator) {
// 当窗口触发计算时(即窗口结束时),此方法被调用。
// distinctUsers集合的大小就是该窗口内独立用户的数量。
return new VideoViewCount(accumulator.videoId, (long) accumulator.distinctUsers.size());
}
@Override
public Accumulator merge(Accumulator a, Accumulator b) {
// 对于会话窗口等可能发生窗口合并的场景,需要实现此方法。
// 对于滚动窗口,此方法通常不会被调用。
a.distinctUsers.addAll(b.distinctUsers);
return a;
}
}
}
深度解析:Flink如何实现端到端的Exactly-Once
要实现真正的端到端Exactly-Once,意味着数据从源头(Source)到最终存储(Sink)的整个处理流程中,每一条记录都只被精确地处理一次,即使在发生故障的情况下也能保证。Flink通过结合**分布式快照(Distributed Snapshots)和两阶段提交(Two-Phase Commit, 2PC)**协议来实现这一目标。
分布式快照 (Checkpointing)
- 核心思想: Flink的JobManager会定期向数据流中注入一种名为**检查点分界线(Checkpoint Barrier)**的特殊记录。这些Barrier会随着数据流经所有的Operator。
- 状态保存: 当一个Operator接收到Barrier时,它会立即暂停处理,将自己当前的状态(例如,窗口内的计数值、已处理的偏移量等)异步地保存到一个持久化存储(如HDFS或S3)中。这个保存的状态被称为快照(Snapshot)。
- 对齐操作: 对于有多个输入流的Operator,它会等待所有输入流的Barrier都到达后,才执行快照,以确保快照的一致性。这个过程被称为Barrier对齐。
- 故障恢复: 如果发生故障,Flink会停止作业,从最近一次成功完成的全局快照中恢复所有Operator的状态,并重置数据源(如Kafka)的读取位置到快照中记录的偏移量。这样,数据可以从上一个一致性的状态点开始重新处理,避免了数据丢失或重复计算。
两阶段提交 (Two-Phase Commit Sink)
- 问题: 仅有Checkpoint不足以保证端到端的Exactly-Once。因为在将结果写入外部系统(如数据库)时,如果在Checkpoint完成之后、数据写入之前发生故障,可能会导致数据重复写入。
- 解决方案: Flink提供了
TwoPhaseCommitSinkFunction(或GenericWriteAheadSink)来解决这个问题。它将数据写入过程分为两个阶段:- 预提交 (Pre-commit): 在一个事务中,数据被写入到外部系统的临时区域。这个事务的状态会作为Operator状态的一部分被包含在下一次的Checkpoint中。
- 提交 (Commit): 当Flink的JobManager收到所有Operator都已成功完成对应Checkpoint的通知后,它会向所有Operator发出一个“提交”指令。此时,Sink才正式将预提交阶段写入的临时数据变为永久可用。
- 原子性保证: 如果在预提交后、提交前发生故障,系统恢复后会从上一个Checkpoint重启。由于外部系统的事务尚未提交,恢复过程可以安全地丢弃这些未提交的事务,从而避免了重复写入。
通过这种Checkpointing + 2PC的协同工作,Flink能够确保即使在分布式环境下频繁发生故障,数据处理的最终结果仍然是准确且唯一的,为我们的计数系统提供了最高级别的数据一致性保证。
优势与权衡:
- 可扩展性: Kafka 和 Flink 都是为大规模分布式处理而设计的,可以水平扩展以应对极高的流量。
- 持久性: Kafka 的持久化机制保证了事件不会因服务崩溃而丢失。
- 最终一致性: 通过10分钟的窗口聚合,满足了最终一致性的要求。
- 幂等性: 在 Flink 消费端进行去重,保证了计数的准确性。
- 性能: 写入路径异步化,对用户请求的响应极快。读取路径通过缓存保证了低延迟。
权衡: 该方案引入了 Kafka 和 Flink,增加了系统的复杂性和运维成本。对于病毒式视频带来的流量洪峰,可能需要专门的 Kafka 集群或更精细的资源调配策略来应对,这是一种在满足业务需求下的可接受的复杂性权衡。
6. 总结
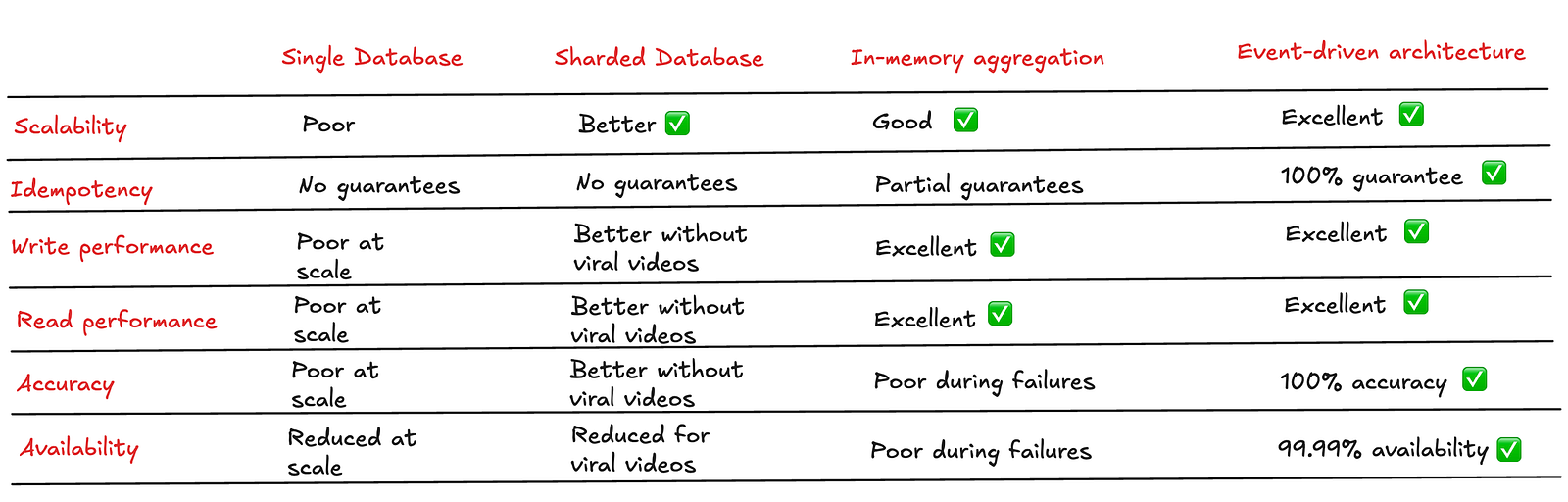
设计一个超高并发用户的流媒体视频平台的分布式计数系统,远非简单的加法运算。它要求我们在准确性、可扩展性、持久性和性能之间做出精妙的权衡。
本文通过四次架构迭代,最终构建了一个基于 Kafka 和 Flink 的事件驱动流处理系统,该系统有效地解决了设计中的各项挑战:
| 挑战 | 解决方案 |
|---|---|
| 高并发写入 | Kafka 提供高吞吐、低延迟的事件缓冲。 |
| 数据持久性 | Kafka 的日志存储机制保证了数据不丢失。 |
| 最终一致性 | Flink 的窗口聚合机制满足了延迟要求。 |
| 幂等性 | 在 Flink 消费端结合状态存储进行事件去重。 |
| 读取性能 | 缓存 + 数据库的模式保证了低延迟读取。 |
本文所描述的设计思路和演进过程,不仅适用于视频观看计数,也可以推广到其他需要大规模计数的场景,如网页浏览量、广告点击量、社交媒体点赞数等。