API版本控制:一个尚未被优雅解决的难题
API版本控制:一个尚未被优雅解决的难题
1. 面临的实际业务场景
在软件产品的生命周期中,API(应用程序编程接口)的迭代和演进是不可避免的。随着业务需求的快速变化、新功能的增加或技术架构的重构,我们常常需要对API进行“破坏性变更(Breaking Changes)”。然而,在分布式系统中,客户端(如移动App、Web前端或其他微服务)的更新速度并不可控。
核心业务场景:当一个API已经被成千上万的活跃用户或系统集成使用时,任何破坏性变更都可能导致现有应用瘫痪。例如,一个V1版本的API返回的用户数据结构,可能无法满足V2版本全新的业务需求。如何在不中断老用户服务的前提下,平滑地发布新版API,并引导用户迁移,是所有开发团队都必须面对的严峻挑战。
 图片说明:AI生成,象征着在API演进道路上的多种选择与复杂性。
图片说明:AI生成,象征着在API演进道路上的多种选择与复杂性。
API版本控制的本质,是在推动创新与保持向后兼容之间寻求平衡,管理API从诞生、演进到废弃的整个生命周期。
2. 技术场景的挑战
理想的API版本控制策略不存在,每种方法都有其固有的技术挑战:
- 多版本共存的复杂性:在代码库中同时维护多个版本的逻辑,会显著增加代码的冗余和复杂度,形成所谓的“历史技术债”。
- 客户端升级的摩擦:强制所有客户端在同一时间点升级是不现实的。版本控制必须假设新旧客户端会长期并存。
- 路由与寻址的混乱:如何清晰、直观地将一个请求路由到其期望的API版本实现,直接影响了API的可发现性和易用性。
- 调试与监控的困难:当版本信息不明确时(例如隐藏在请求头中),快速定位问题、调试和监控特定版本的API流量会变得异常困难。
- 维护成本高昂:每个新版本的引入都意味着额外的开发、测试和维护成本。如果没有一个清晰的废弃策略,这些成本会无限累积。
3. 对于挑战的技术解决方案
业界主流的API版本控制策略主要有以下几种,但更推荐一种能够隔离变化的“适配器模式”架构。
3.1. 主流版本控制策略
3.1.1. URL路径版本控制 (URL Path Versioning)
在URL中直接嵌入版本号,是最直观和常见的方式。
- 原理:通过不同的URL路径指向不同的API版本实现。
- 示例代码:
// 版本 V1 GET /api/v1/users/123 // 版本 V2 GET /api/v2/users/123 - 优缺点:
- 优点:版本明确,直观易懂,便于浏览器直接访问和调试。可以方便地利用HTTP缓存。
- 缺点:污染了URL的语义,不符合RESTful风格中“一个资源只有一个唯一URI”的原则。易导致路由代码重复。
3.1.2. 请求头版本控制 (Header Versioning)
通过自定义请求头或Accept头来传递版本信息。
- 原理:保持URL不变,客户端在HTTP请求头中指定所需版本。
- 示例代码:
GET /api/users/123 Headers: { "X-API-Version": "2.0", // 自定义请求头 "Accept": "application/vnd.myapi.v2+json" // 通过Accept头 } - 优缺点:
- 优点:保持URL的纯净和持久性,更符合RESTful理念。
- 缺点:版本信息被隐藏,不直观,增加了调试难度。无法通过浏览器直接测试不同版本。
3.1.3. 查询参数版本控制 (Query Parameter Versioning)
将版本号作为URL的查询参数。
- 原理:通过URL查询字符串来指定版本。
- 示例代码:
GET /api/users/123?version=2 - 优缺点:
- 优点:实现简单,也相对直观。
- 缺点:同样污染URL,且容易与业务过滤参数混淆。
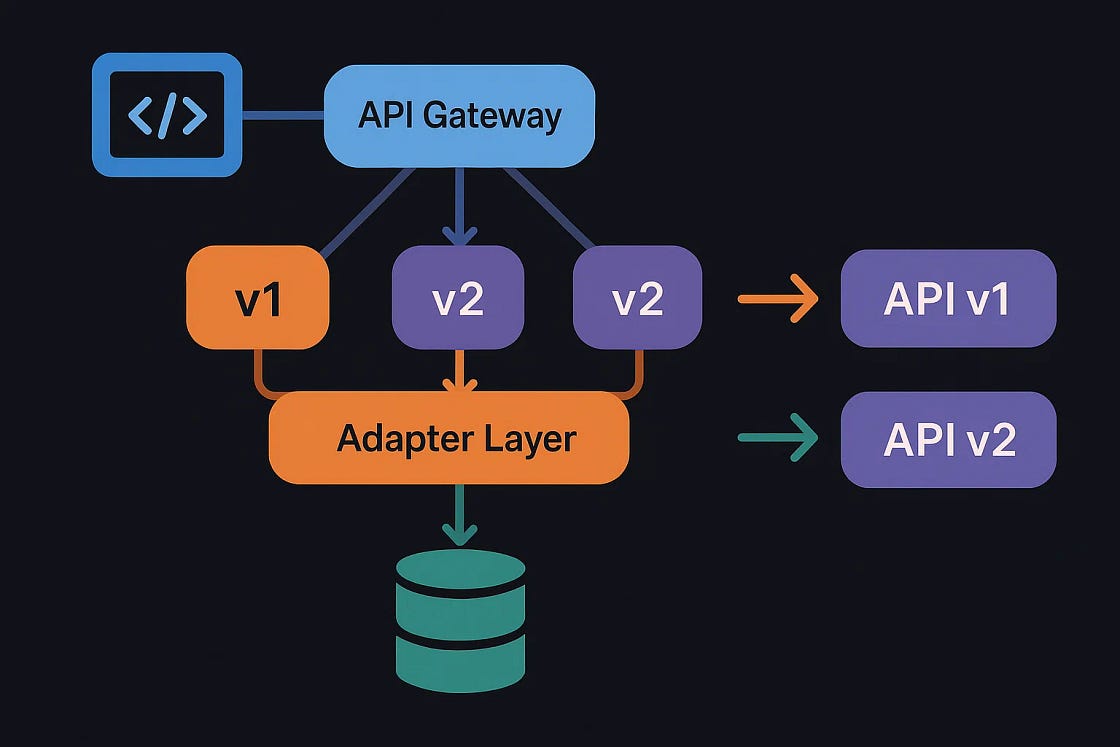
3.2. 推荐架构:基于适配器模式的解决方案
为了从根本上解决代码重复和维护难题,推荐采用一种混合方法,将版本处理逻辑与核心业务逻辑解耦。
3.2.1. 架构原理
该架构的核心思想是:保持核心业务逻辑的版本无关性。所有特定版本的处理,如下发数据结构的转换、请求参数的适配等,都通过独立的“适配器层(Adapter Layer)”来完成。
┌────────────────────────────────────────────────────────┐
│ API网关 (API Gateway) │
├────────────────────────────────────────────────────────┤
│ 路由检测 & 版本解析 (Route & Version Resolution) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ V1 路由 │ │ V2 路由 │ │ V3 路由 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
├────────────────────────────────────────────────────────┤
│ 版本适配器层 (Version Adapter Layer) │
│ ┌─────────────────────────────────────────────────────┤
│ │ 转换 V1 -> 核心模型 │ 转换 V2 -> 核心模型 │
│ └─────────────────────────────────────────────────────┤
├────────────────────────────────────────────────────────┤
│ 核心业务逻辑 (Core Business Logic) │
│ (版本无关 Version Agnostic) │
├────────────────────────────────────────────────────────┤
│ 数据访问层 (Data Access Layer) │
└────────────────────────────────────────────────────────┘
3.2.2. 代码实现示例 (Python with FastAPI)
1. 核心服务层 (Core Service Layer)
该层完全不感知API版本,只处理标准化的内部数据模型。
'''
核心用户服务,处理与版本无关的业务逻辑。
'''
class UserService:
def get_user(self, user_id: str) -> UserModel:
"""
根据用户ID获取用户数据。
这里的UserModel是内部统一的数据模型,与任何API版本的数据结构无关。
"""
# 版本无关的核心逻辑
return self.repository.find_by_id(user_id)
def update_user(self, user_id: str, data: dict) -> UserModel:
"""
更新用户信息,业务逻辑只在这里处理一次。
"""
validated_data = self.validate_user_data(data)
return self.repository.update(user_id, validated_data)
2. 版本专用适配器 (Version-Specific Adapters)
每个版本都有一个适配器,负责将核心数据模型转换为该版本特定的响应格式。
'''
V1版本的用户数据适配器。
'''
class UserV1Adapter:
def transform_response(self, user: UserModel) -> dict:
"""
将核心UserModel转换为V1版本的API响应格式。
"""
return {
"id": user.id,
"name": user.full_name,
"email": user.email_address
}
'''
V2版本的用户数据适配器。
'''
class UserV2Adapter:
def transform_response(self, user: UserModel) -> dict:
"""
将核心UserModel转换为V2版本的API响应格式,结构发生了变化。
"""
return {
"user_id": user.id,
"profile": {
"display_name": user.full_name,
"contact_email": user.email_address,
"created_at": user.created_timestamp
}
}
3. 智能路由层 (Smart Routing)
在API入口处(如Controller或FastAPI的路由函数),根据版本信息选择合适的适配器。
from fastapi import FastAPI, Header
from typing import Optional
app = FastAPI()
@app.get("/users/{user_id}")
async def get_user(
user_id: str,
# 通过请求头获取版本信息,默认为1.0
api_version: Optional[str] = Header("1.0", alias="X-API-Version")
):
# 1. 调用核心服务,获取版本无关的用户数据
user = UserService().get_user(user_id)
# 2. 根据版本号,选择对应的适配器进行数据转换
if api_version.startswith("2"):
return UserV2Adapter().transform_response(user)
else:
return UserV1Adapter().transform_response(user)
3.3. 基于AWS API Gateway的实现方案
借助AWS云原生服务,我们可以将“适配器模式”思想完美落地,构建一个高可用、可扩展且易于维护的API版本控制系统。
3.3.1. 架构设计
该方案使用 AWS API Gateway 作为流量入口和路由中心,使用 AWS Lambda 作为版本适配器和核心业务逻辑的载体。
+----------+ +--------------------------------+ +----------------------+ +---------------------+
| Client |-->| AWS API Gateway |----->| Lambda Adapter (V1) |----->| |
+----------+ | | +----------------------+ | Core Business Logic|
| Route /v1/* -> Lambda-V1 | | (e.g., Lambda/ECS) |
| Route /v2/* -> Lambda-V2 | +----------------------+ | (Versionless) |
| |----->| Lambda Adapter (V2) |----->| |
+--------------------------------+ +----------------------+ +---------------------+
- API Gateway: 负责处理外部请求,并根据URL路径(如
/v1/...或/v2/...)将请求路由到对应的Lambda适配器。 - Lambda Adapter: 每个API版本对应一个独立的Lambda函数(如
api-adapter-v1,api-adapter-v2)。它的唯一职责是:接收API Gateway的请求,调用核心业务逻辑,然后将返回的通用数据模型转换为当前版本特定的数据结构。 - Core Business Logic: 另一个独立的Lambda函数或ECS/EKS服务,它完全不知道版本的存在,只负责处理最纯粹的业务逻辑。
3.3.2. 实现步骤与代码示例
1. 定义API Gateway路由
在API Gateway中,使用路径版本控制策略创建资源,例如:
/v1/users/{userId}/v2/users/{userId}
将每个路径分别配置为对不同Lambda适配器的“Lambda函数集成”。
2. 编写Lambda适配器 (api-adapter-v1)
这个Lambda函数是连接API Gateway和核心业务逻辑的桥梁。
# lambda_adapter_v1.py
import json
import boto3
# 初始化boto3客户端,用于调用其他Lambda
lambda_client = boto3.client('lambda')
# 假设UserModel和UserV1Adapter定义在共享层(Lambda Layer)或打包在部署包中
from shared.models import UserModel
from shared.adapters import UserV1Adapter
def lambda_handler(event, context):
"""
API Gateway V1版本适配器
"""
try:
# 1. 从API Gateway传入的event中解析参数
user_id = event['pathParameters']['userId']
# 2. 同步调用核心业务逻辑Lambda
invocation_response = lambda_client.invoke(
FunctionName='core-business-logic-service',
InvocationType='RequestResponse',
Payload=json.dumps({'action': 'getUser', 'userId': user_id})
)
# 读取并解析核心服务的返回
core_payload = json.loads(invocation_response['Payload'].read())
if core_payload.get('error'):
raise Exception(core_payload['error'])
# 将返回的dict转换为内部数据模型
user_model = UserModel(**core_payload['data'])
# 3. 使用V1适配器转换数据模型为V1响应格式
v1_response_body = UserV1Adapter().transform_response(user_model)
# 4. 构造并返回符合API Gateway代理集成格式的响应
return {
'statusCode': 200,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps(v1_response_body)
}
except Exception as e:
# 统一异常处理
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
3. 编写核心业务逻辑Lambda (core-business-logic-service)
这个Lambda非常纯粹,只负责业务处理。
# core_logic_lambda.py
def lambda_handler(event, context):
"""
处理核心业务逻辑,版本无关
"""
action = event.get('action')
user_id = event.get('userId')
if action == 'getUser':
# ... 从数据库或其他服务获取数据的逻辑 ...
user_data = get_user_from_db(user_id)
# 以dict或标准内部模型格式返回
return {'data': user_data}
return {'error': 'Unknown action'}
3.3.3. 方案优缺点
优点:
- 完全托管与高可用:API Gateway和Lambda都是AWS的完全托管服务,自带高可用和弹性伸缩能力。
- 关注点分离清晰:路由(API Gateway)、适配(Lambda Adapter)、业务逻辑(Core Logic)在物理上完全隔离,职责单一。
- 独立部署与迭代:可以独立更新或回滚某个版本的适配器(例如修复V2的bug),完全不影响V1和其他版本。
- 精细化安全控制:可使用IAM角色为每个服务间的调用进行精细化的权限授权。
缺点:
- 延迟增加:请求链条变长(Client -> API GW -> Adapter Lambda -> Core Lambda),会引入额外的网络延迟。Lambda的冷启动问题也需要关注和优化。
- 架构复杂度:相比单体应用,需要管理和监控的组件更多,对DevOps和可观测性提出了更高要求。
- 成本考量:成本模型基于请求数和计算时长,对于流量波动大的场景非常经济;但对于持续高流量场景,需与基于EC2的成本模型进行比较。
4. 生产落地考虑及FAQ
4.1. 性能考量
版本适配器会引入额外的计算开销。以下是一个基准测试的参考:
- 直接响应 (无版本控制): ~0.8ms
- 单层适配器: ~1.2ms
- 多版本支持: ~1.8ms
对于大多数应用,这点开销可以忽略不计。但对于高吞吐量的API,可以考虑以下优化:
- 缓存转换后的响应:在适配器层对转换结果进行缓存。
- 预计算版本负载:在数据写入时,就预先生成并存储不同版本的数据格式。
- 使用高性能序列化库:例如Python的
orjson或Rust的sonic-rs。
4.2. API迁移与废弃策略
一个结构化的迁移计划至关重要。
阶段一: 并行运行 (1-3个月)
┌──────────────┐ ┌──────────────┐
│ 客户端应用 │───▶│ API v1 │
│ (Client App) │ │ (活跃) │
└──────────────┘ └──────────────┘
│
▼ (影子流量)
┌──────────────┐
│ API v2 │
│ (影子模式) │
└──────────────┘
阶段二: 逐步切换 (4-6个月)
┌──────────────┐ ┌──────────────┐
│ 客户端应用 │───▶│ API v1 │
│ (Client App) │ │ (废弃状态) │
└──────────────┘ └──────────────┘
│
▼
┌──────────────┐
│ API v2 │
│ (主版本) │
└──────────────┘
阶段三: 正式下线 (第7个月起)
┌──────────────┐ ┌──────────────┐
│ 客户端应用 │───▶│ API v2 │
│ (Client App) │ │ (唯一版本) │
└──────────────┘ └──────────────┘
4.3. 常见问题 (FAQ)
Q1: 哪种版本控制策略是最好的?
A: 没有“最好”的策略,只有“最适合”的。选择应基于团队的技术栈、开发能力和用户需求。
- URL版本控制虽然粗暴,但其明确性对外部开发者非常友好。
- 请求头版本控制更优雅,适合内部服务间调用。
- 适配器模式虽然增加了架构复杂度,但从长远看,它极大地降低了维护成本,是构建可演进系统的理想选择。
Q2: 如何优雅地废弃一个旧版API?
A:
- 提前通知:通过文档、邮件、
Warning响应头等方式,明确宣布废弃计划和时间表。 - 提供迁移指南:为开发者提供从旧版本迁移到新版本的详细文档。
- 监控旧版使用情况:通过日志和监控,了解哪些客户端仍在使用旧版API,并进行精准沟通。
- 设置“日落”(Sunset)日期:在废弃一段时间后,正式关闭API端点。
Q3: 我们应该从第一天就设计版本控制吗?
A: 是的。不要试图在后期“修补”版本控制。从项目伊始就采用适配器模式等可演进的架构,即使第一个版本只有一个适配器,也能为未来的平滑过渡打下坚实基础。
Q4: 除了版本控制,有其他方法避免破坏性变更吗?
A: 有。最好的策略是尽量进行非破坏性(加法)变更。例如,只增加新的可选字段,而不是修改或删除现有字段。只有在无法避免破坏性变更时,才启用版本控制。
核心思想: API版本控制的终极目标是优雅地管理分布式系统中的变更。最好的策略是你的团队能够持续、一致地执行的策略。为未来着想,从第一天起就构建一个可演进的、版本无关的核心架构,这会让你和你的用户都受益匪-穷。