AI零代码智能数据分析决策助手
一、系统架构
1. 工作流程设计
该智能数据分析决策助手的工作流如下:
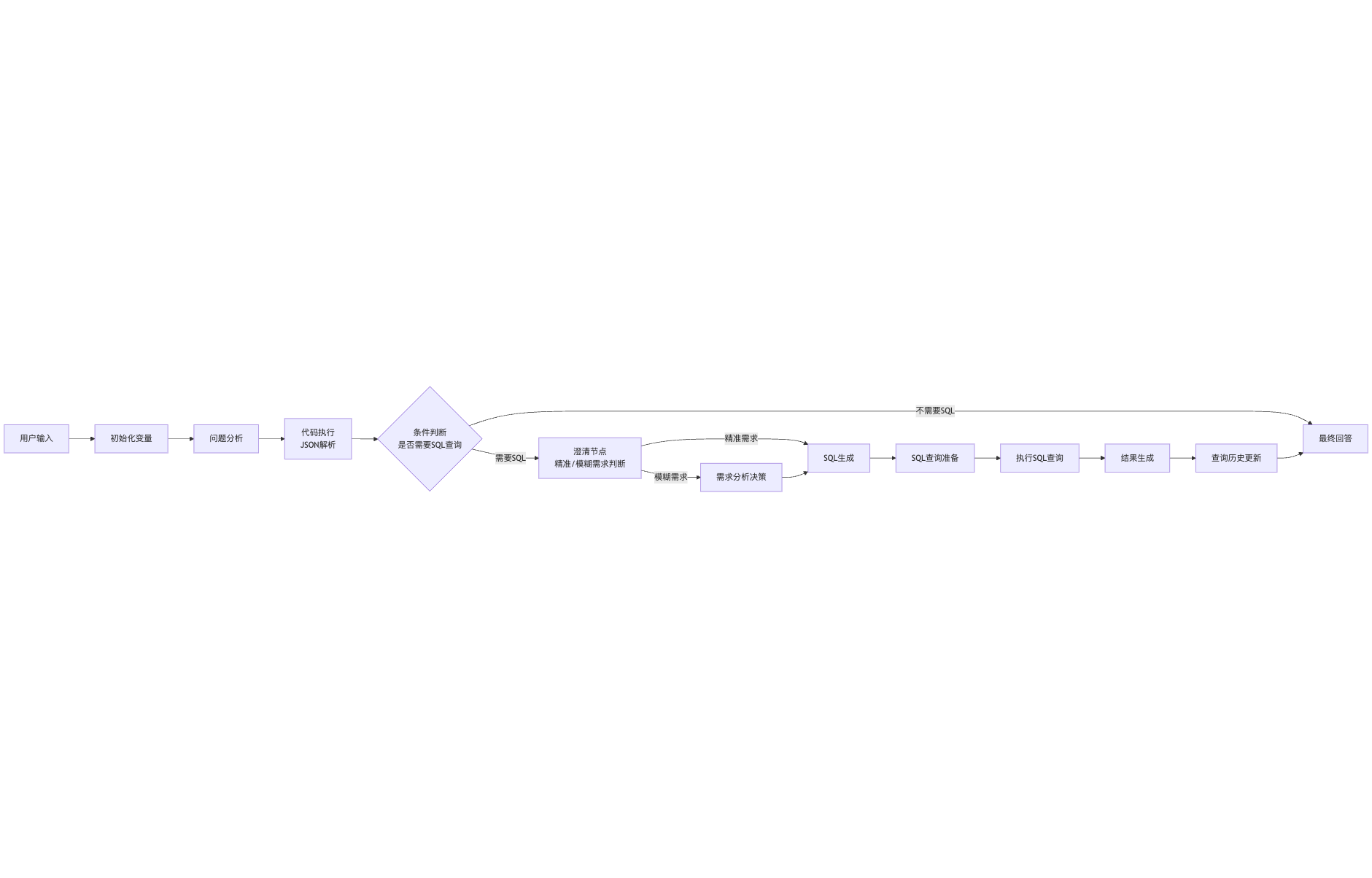
工作流主要分为两条主要路径:
不需要执行SQL查询:直接提供答案
需要执行SQL查询:
- 精准咨询需求:直接进入SQL生成和执行流程
- 模糊咨询需求:先进行需求分析决策,再进入SQL生成和执行流程
例如:
如果用户输入精准需求,例如"按产品类别统计销售总额"
如果用户输入模糊需求,例如"给高消费用户发促销信息"
这两类业务数据分析需求,AI助手都可以自动执行并得到最终结果,整个过程不需要用户写SQL,而且写出的SQL和分析结果都符合用户的业务需求预期
1.1 工作流实际运行效果
精准需求示例
用户明确知道想要查询的内容,直接提出具体需求,例如"按产品类别统计销售总额":
模糊需求示例
用户只有模糊的业务目标,没有明确的查询内容,例如"给高消费用户发促销信息":

2. 核心节点说明
2.1 初始化变量节点
功能: 加载数据库结构(schema)和术语映射
输出: database_schema(String), terminology_mapping(String), query_history(String)
实现: 使用代码执行节点,确保database_schema以JSON字符串形式输出
关键处理:
# 将Object类型转换为String类型以便传递 database_schema_obj = json.loads(database_schema_str) database_schema = json.dumps(database_schema_obj)
2.2 问题分析节点
- 类型: LLM节点
- 模型: DeepSeek-Chat
- 功能: 分析用户输入的问题意图和查询需求
- 输入: 用户输入文本
- 输出: 问题分析结果
2.3 代码执行节点(JSON解析)
- 功能: 解析问题分析结果,提取关键信息
- 输入: 问题分析节点的输出
- 输出:
- needs_sql(Number): 1表示需要SQL,0表示不需要
- 其他结构化信息
- 关键逻辑: 对LLM输出进行结构化处理,转换为工作流可使用的变量
2.4 条件判断节点
- 功能: 根据needs_sql值选择流程分支
- 条件: 检查needs_sql变量值
- 分支:
- 当needs_sql=1时:转向澄清节点
- 当needs_sql=0时:直接回答
2.5 澄清节点(精准/模糊需求判断)
- 类型: LLM节点
- 模型: DeepSeek-Chat
- 功能: 判断用户需求是精准需求还是模糊需求
- 输出: 需求类型判断结果
- 分支:
- 精准需求:直接进入SQL生成流程
- 模糊需求:进入需求分析决策流程
2.6 需求分析决策节点
- 类型: LLM节点
- 模型: DeepSeek-Chat
- 功能: 对模糊需求进行深入分析,确定具体查询需求
- 输入: 用户输入文本、澄清节点结果
- 输出: 具体化的查询需求
2.7 SQL生成节点
- 类型: LLM节点
- 模型: DeepSeek-Coder
- 功能: 根据用户需求生成PostgreSQL查询
- 输入: database_schema(String), 用户需求(精准需求或经分析的模糊需求)
- 提示词: 包含数据库结构信息和精确查询要求
- 输出: SQL查询代码
2.8 SQL查询准备节点
- 类型: 代码执行节点
- 功能: 处理SQL代码,准备执行
- 输入: SQL生成节点输出的SQL代码
- 输出: 准备执行的SQL查询语句
- 处理内容: 清理SQL代码中的markdown标记,格式化SQL
2.9 SQL查询执行节点
类型: 代码执行节点
功能: 通过Python代码直接发送SQL查询
实现:
def main(sql_query: str) -> dict: import requests import json # 构建请求 url = "http://api-endpoint/query" payload = {"sql": sql_query} headers = {"Content-Type": "application/json"} # 发送请求 response = requests.post(url, json=payload, headers=headers) # 返回结果 return { "success": 1 if response.status_code == 200 else 0, "data_json": json.dumps(response.json()) if response.status_code == 200 else "{}", "status_code": response.status_code, "error": response.text if response.status_code != 200 else "" }输入: sql_query(String)
输出: success(Number), data_json(String), status_code(Number), error(String)
2.10 结果生成节点
- 类型: LLM节点
- 模型: DeepSeek-Chat
- 功能: 解析查询结果并生成自然语言解释
- 输入: data_json(String), query_success(Number), error_msg(String), user_query(String)
- 输出: 格式化的查询结果解释
2.11 查询历史更新节点
- 类型: 代码执行节点
- 功能: 记录查询历史和结果
- 输入: query_history(String), user_query(String), result_text(String)
- 输出: 更新后的query_history(String)
3. 工作流优化要点
3.1 模型选择说明
- DeepSeek-Chat: 用于问题分析、澄清判断、需求分析决策和结果生成等自然语言处理任务
- 理由:DeepSeek-Chat对自然语言理解和生成有较好的能力,且API格式要求较为简单
- DeepSeek-Coder: 用于SQL生成节点
- 理由:具有更强的代码生成能力,适合生成结构化的SQL查询
3.2 类型处理优化
确保条件节点使用的变量类型匹配(Number对Number)
使用JSON字符串(String类型)而非Object类型传递复杂数据结构
变量类型转换处理:
# 例如:确保needs_sql为数值类型 needs_sql = int(bool(needs_sql))
3.3 变量传递优化
- 避免使用节点名前缀访问变量(如
代码执行.needs_sql) - 直接使用变量名(如
needs_sql) - 使用字符串形式传递JSON数据,避免Object类型传递问题:
# 转换为字符串
data_json = json.dumps(result)
3.4 DeepSeek模型API适配
针对DeepSeek模型的API要求,需要进行特殊处理:
# 适配DeepSeek模型的消息格式要求 messages = [ {"role": "system", "content": "你是一个数据分析助手"}, {"role": "user", "content": prompt} ]确保消息格式符合API要求,避免连续相同角色消息和格式错误
二、技术实现
1. LLM集成
1.1 DeepSeek-Chat配置
- 用途: 问题分析、需求类型判断、需求分析决策、结果生成
- 关键参数:
- 模型: deepseek-chat
- 温度: 0.7
- 最大长度: 2048
- Top P: 0.95
- 注意事项:
- 确保消息格式正确
- 避免连续同类型角色消息
1.2 DeepSeek-Coder配置
用途: SQL代码生成
关键参数:
- 模型: deepseek-coder
- 温度: 0.3
- 最大长度: 2048
- Top P: 0.95
注意事项:
提供完整的数据库结构信息
在提示词中指定PostgreSQL语法要求
2. 数据处理
2.1 JSON解析和处理
- 使用Python json模块处理JSON数据
- 异常处理确保解析错误不会导致流程中断
- 转换类型以适应工作流需求
2.2 SQL查询处理
- 清理SQL代码中的markdown标记
- 格式化SQL以确保可执行性
- 通过API发送SQL并获取结果
2.3 查询结果处理
- 解析查询结果JSON
- 转换为结构化数据供LLM解释
- 生成格式化的回答
3. 错误处理
3.1 LLM输出解析错误
- 设置默认值确保流程连续性
- 记录错误信息以便调试
- 提供友好的错误提示
3.2 SQL执行错误
- 捕获和处理SQL语法错误
- 数据库连接错误处理
- 结果格式化错误处理
3.3 API调用错误
- 请求超时处理
- 服务不可用时的降级策略
- 重试机制设计
三、部署说明
1. 环境要求
- Python 3.10+
- 必要的Python包:
- requests
- json
- flask (API服务)
- psycopg2 (PostgreSQL连接)
2. 配置说明
- LLM API配置:
- DeepSeek API密钥
- 端点URL
- 请求超时设置
- 数据库连接配置:
- 主机地址
- 端口
- 用户名和密码
- 数据库名称
3. 部署步骤
- 安装依赖包
- 配置环境变量
- 初始化数据库连接
- 启动API服务
- 配置工作流节点
四、工作流文件
工作流配置文件可以在以下链接查看:AI零代码智能数据分析决策助手.yml
五、模拟后端API服务说明
本项目使用了基于Flask的模拟后端API服务来支持数据分析和SQL查询功能。关于该服务的详细说明,包括接口描述、数据库结构、环境配置和使用方法等,请参考database-api-service目录下的README.pdf文件。
该服务为AI零代码智能数据分析决策助手提供了必要的后端支持,可直接通过API调用执行SQL查询并获取数据分析结果。
GitHub地址:database-api-service