Agentic RAG 技术详解:从基本检索到智能代理
Agentic RAG 技术详解:从基本检索到智能代理
1. 背景:传统 RAG 的局限性
检索增强生成 (Retrieval-Augmented Generation, RAG) 是一种通过从外部知识库检索相关信息,来增强大型语言模型(LLM)回答准确性的有效技术。传统的 RAG 系统通常遵循一个线性的、固定的处理流程:
- 接收查询 (Receive Query):接收用户的原始问题。
- 信息检索 (Retrieve):将查询转化为嵌入向量,在向量数据库中进行相似度搜索,找出最相关的文本片段(Chunks)。
- 内容增强 (Augment):将检索到的文本片段与原始问题拼接成一个更丰富的提示(Prompt)。
- 生成答案 (Generate):将增强后的提示送入 LLM,生成最终的回答。

然而,这种固定的流程在面对复杂问题时,会暴露出明显的局限性。它本质上是一个“一次性”的检索,如果初次检索到的信息不准确或不完整,整个回答的质量就会大打折扣。它缺乏思考、推理和自我修正的能力。
2. 核心理念:什么是 Agentic RAG?
Agentic RAG 是对传统 RAG 的一种演进,其核心思想是赋予系统**“代理能力”(Agency)**。这意味着系统不再是被动地执行一个固定的工作流,而是能够像一个智能代理(AI Agent)一样,自主地思考、决策并采取一系列行动来解决用户的问题。
从“程序性工作流”到“AI 代理”的关键转变在于:
- 程序性工作流:开发者在代码中命令式地定义好每一步操作的顺序。
- AI 代理:开发者为代理提供一个目标和一套可用的工具(Tools),由代理(通常是 LLM 本身)来自主决定采取哪些步骤、使用哪些工具,以及何时结束。
在 Agentic RAG 中,LLM 不再仅仅是答案的“生成器”,更是整个问题解决过程的“大脑”和“调度中心”。
3. Agentic RAG 的工作原理与架构
Agentic RAG 的实现依赖于一个更加精密和强大的处理循环,并可以通过引入“模型上下文协议”(MCP)等高级模式来管理复杂的数据源。
3.1 增强的 Agentic 处理循环
一个更成熟的 Agentic RAG 系统,其处理循环远不止“调用工具”这么简单,它包含了一系列更精细的步骤:
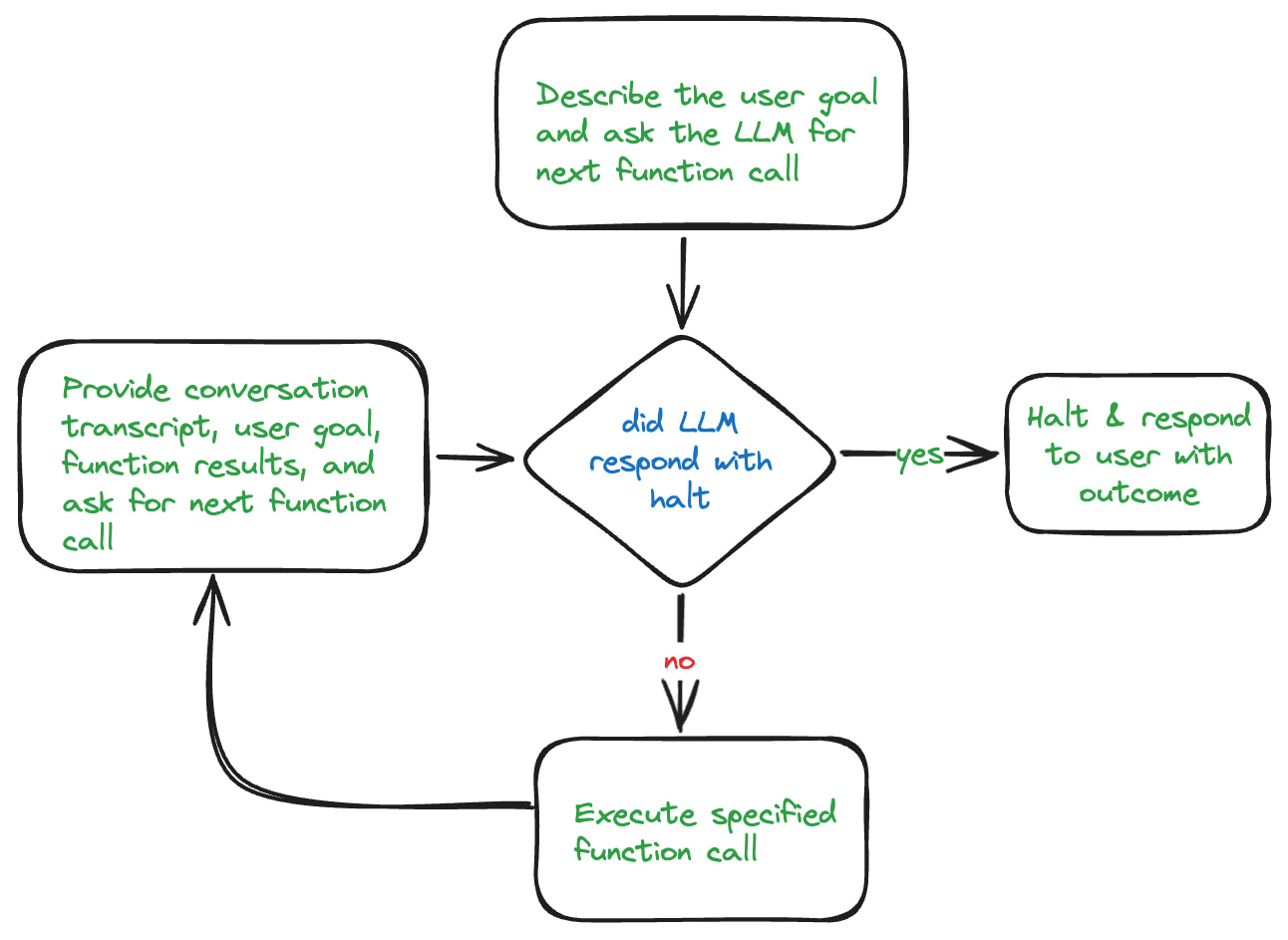
查询分析 (Query Analysis):接收到用户原始查询后,第一个 Agent(或 LLM)会对其进行分析。这个阶段可能包括:
- 查询重写 (Query Rewriting):为了提升检索质量,可能会对原始查询进行改写,甚至分解成多个子查询。
- 决策是否需要检索 (Retrieval Decision):判断仅凭对话历史是否足以回答问题,还是必须从外部数据源检索额外信息。
信息检索 (Retrieval):如果需要检索,系统会从一个或多个数据源中获取信息。这些数据源可能包括:
- 实时的用户数据
- 内部文档或知识库
- 公开的网页信息
- 结构化的数据库
重排序与精炼 (Rerank & Refine):从多个来源检索到的信息可能是海量的、有噪音的。因此,通常会使用一个更强大的模型(如专门的 Reranker 模型)对检索结果进行重排序,筛选出与查询最相关、信息量最大的少数几个文档。
答案生成 (Generation):将经过精炼的上下文信息和原始查询(或重写后的查询)结合,交由 LLM 生成最终的答案、执行某个动作,或形成下一步计划。
评估与迭代 (Evaluate & Iterate):另一个 Agent(或 LLM)会对生成的答案进行“反思”和评估。
- 如果答案质量高、相关性强,则将其返回给用户。
- 如果答案不理想,Agent 可以决定重写查询,并重新进入第二步(信息检索),开始新一轮的循环,直到获得满意的答案或达到最大尝试次数。
3.2 关键设计:作为“工具”的检索函数
Agentic RAG 与传统 RAG 在设计上的核心区别,在于将检索操作封装成一个个具体的**“检索函数”(Retrieval Functions)**,作为工具供 LLM 选择。
实践证明,设计小而具体的函数,比设计一个大而全的复杂函数效果更好。例如,与其提供一个需要 LLM 自己构造复杂查询参数的通用 vectorSearch 函数,不如提供几个更直接的函数:
searchDocs(query: str): 专门用于搜索产品文档。searchForums(query: str): 专门用于搜索社区支持论坛。escalateToHuman(summary: str): 用于上报给人工支持。
这种方式抽象了底层的复杂性,降低了 LLM 的决策难度,使其能更准确地选择正确的工具来执行任务。
3.3 引入模型上下文协议 (MCP) 进行数据源管理
当 Agentic RAG 系统需要对接多种异构数据源(如实时用户数据、内部文档、Web 数据等)时,直接让 AI Agent 了解每个数据源的细节(如何访问、有何权限、数据格式等)会变得非常复杂且难以维护。
模型上下文协议 (Model Context Protocol, MCP) 应运而生,旨在解决这一问题。MCP 的核心思想是定义一个标准化的协议,用于规范 AI Agent 和底层数据源(上下文提供方)之间的交互。
MCP 如何工作?
它位于 Agentic RAG 流程的第 2 步(信息检索)。当 Agent 决定需要检索信息时,它不再是直接调用某个数据源的特定工具,而是通过一个遵循 MCP 协议的标准化接口,向一个**“MCP 服务池”**发出请求。池中的每个数据源都通过一个遵循该协议的 Server 对外提供服务。
MCP 带来的核心优势:
- 去中心化的数据管理:每个数据域(如“用户数据域”、“产品文档域”)都可以部署和管理自己的 MCP Server。数据所有者可以在自己的 Server 上,根据协议规范,来定义其数据的使用规则、访问策略和更新逻辑。
- 统一的安全与合规:安全和合规策略可以在每个 MCP Server 上得到强制执行,确保数据访问符合规范,而不是将安全逻辑分散在 AI Agent 的代码中。
- 解耦与可扩展性:
- 当需要添加一个新的数据源时,只需开发一个新的、遵循 MCP 协议的 Server 并将其注册到服务池中即可,AI Agent 的核心逻辑无需任何修改。
- 这种方式实现了不同类型内存(如程序性内存、情景记忆、语义记忆)的解耦演进。
- 标准化的数据暴露:平台构建者可以为内部甚至外部消费者,提供一个标准化的数据访问协议,简化了数据共享。
- 关注点分离:AI 工程师可以更专注于设计 Agent 的拓扑结构和推理逻辑,而数据工程师则可以专注于优化其领域内的 MCP Server 和底层数据。
4. 构建高质量 Agentic RAG 的实践要点
要让 Agentic RAG 可靠地工作,除了优秀的架构设计,还需要在多个层面进行细致的优化。
4.1 提示工程 (Prompt Engineering)
提示(Prompt)是引导 LLM 行为的关键。以下是一些被证明有效的提示策略:
- 明确指令与约束:在系统提示中明确告知 LLM 其角色、可用工具,以及在不确定时应采取的行动。例如,加入“除非你确信有准确的答案,否则不要自行编造,应使用
escalateToHuman工具上报问题”这样的指令,可以显著提高系统的可靠性。 - 利用历史对话:LLM 可能会“忘记”在之前的循环中已经发现的信息,从而进行重复的工具调用。通过在提示中加入“请参考对话记录中你已经获得的发现”这样的指令,可以引导 LLM 更好地利用上下文,避免冗余操作。
- 关于思维链(Chain of Thought):对于需要多步、可重复的数学或逻辑推理问题,CoT 技术非常有效。但对于客户支持这类开放性问题,其效果可能不明显。
4.2 模型与结构化输出 (Model Choice and Structured Output)
- 模型能力:Agentic RAG 的表现与 LLM 的推理能力强相关。通常,更大、更先进的模型(如 GPT-4o)在遵循指令和进行工具选择方面表现得比小模型(如 Llama3.1 8B)更可靠。
- 结构化输出:早期的 LLM 在生成严格格式的 JSON(用于函数调用)时,常常会出错,导致应用层解析失败,中断处理循环。使用支持“结构化输出”或“JSON 模式”(如 OpenAI 的
strict=true模式)的新一代模型,是实现稳定 Agentic RAG 的一个技术突破点,它能确保 LLM 的输出始终是可被程序解析的有效 JSON。
4.3 RAG 管道的重要性 (The Importance of the RAG Pipeline)
Agentic RAG 并非银弹,它只是在上层增加了一层智能调度。其最终效果的基石,仍然是一个高质量的传统 RAG 管道。这意味着:
- 数据质量:输入的数据源(文档、论坛、知识库)必须内容准确、信息丰富。
- 数据处理:分块(Chunking)策略、嵌入模型(Embedding Model)的选择、索引的构建等数据工程挑战,依然是整个系统中最繁琐但至关重要的一环。
- 信息时效性:必须有自动化的 RAG 管道来确保持续地从数据源摄取最新信息,避免向量索引库中的信息变得陈旧。
5. 展望:自主与多智能体系统
Agentic RAG 的概念可以进一步扩展:
- 多智能体系统 (Multi-Agent Systems):对于更复杂的任务,可以将责任拆分给多个协同工作的智能体。例如,一个“查询分析代理”负责理解用户意图,一个“检索代理”负责执行搜索,一个“答案生成代理”负责组织语言,它们共同协作完成任务。
- 自主代理 (Autonomous Agents):在某些场景下(如内容审核、侵权检测),代理甚至不需要用户的实时交互。它们可以被事件驱动,自主地发现问题、设定目标并执行解决流程。
6. 总结
Agentic RAG 通过引入代理(Agent)的概念,将传统 RAG 的线性工作流,升级为一个由 LLM 驱动的、能够自主决策和使用工具的动态处理循环。通过引入 MCP (模型上下文协议) 等高级模式,可以进一步解耦和标准化对多种异构数据源的访问,使系统更具扩展性和可维护性。然而,要构建一个稳定、可靠的 Agentic RAG 系统,不仅需要巧妙的架构设计,更离不开高质量的底层 RAG 数据管道、精细的提示工程以及对先进 LLM 特性(如结构化输出)的善用。