基于Amazon Serverless的智能辅助驾驶数据注入管理平台
基于Amazon Serverless的智能辅助驾驶数据注入管理平台
最近几个月也一直在进行云计算在智能辅助领域的技术调研,参考研究了亚马逊云开发者的文远知行的案例,也调研学习了AWS的官网文档和技术博客,进行了更加深入的总结。如下是进行的总结。
1. 前言
智能辅助驾驶技术研发高度依赖数据,随着智能辅助驾驶车队规模扩大,数据采集、处理和管理变得日益复杂。本文介绍某智能辅助驾驶算法解决方案开发公司如何利用Amazon Serverless相关服务构建低成本、免运维和高安全性的数据注入管理平台。
智能辅助驾驶公司需要不断从现场道路测试中收集数据用于模型训练、算法测试和模拟仿真。随着车辆数量增加,每天产生TB级数据,且需要跨区域进行采集和管理,这对数据处理系统提出了更高要求。
2. 系统概述
2.1 业务需求
- 处理多地测试车队大规模数据上传
- 自动化数据解密、分类和索引
- 提供安全可靠的API接口
- 降低运维成本,提高系统弹性
- 确保跨区域数据管理的一致性
2.2 系统架构
基于Amazon Serverless服务构建的平台架构主要包含三个层次:数据处理层、API网关层和管理服务层。
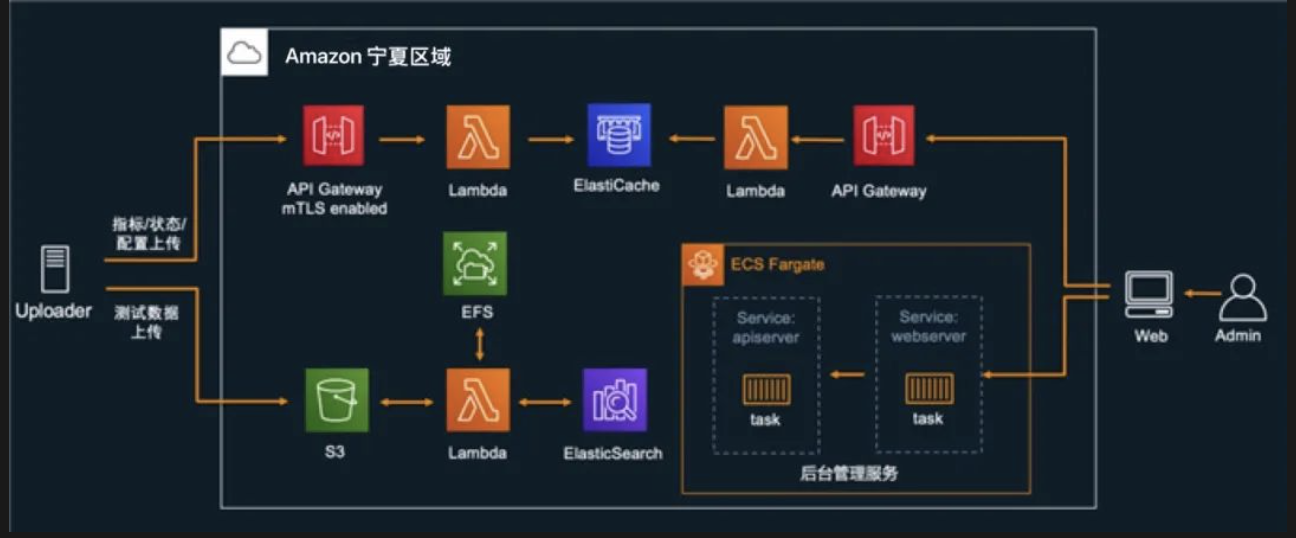
架构特点:
- 数据处理层:利用S3存储、Lambda函数和ElasticSearch实现数据自动处理和索引
- API网关层:通过API Gateway与mTLS认证保障安全通信
- 管理服务层:使用ECS和Fargate提供无服务器容器管理
3. 数据采集与上传流程
3.1 数据上传工作流程
测试车辆通过各种传感器收集数据后,经由Uploader进行处理并上传至云端:
- 车辆采集数据存储在随车硬盘上
- 收车后,硬盘连接至车库的Uploader服务器
- Uploader自动分析、加密并上传关键数据
- 数据上传至Amazon S3存储桶
- 上传状态实时显示在车库显示屏上
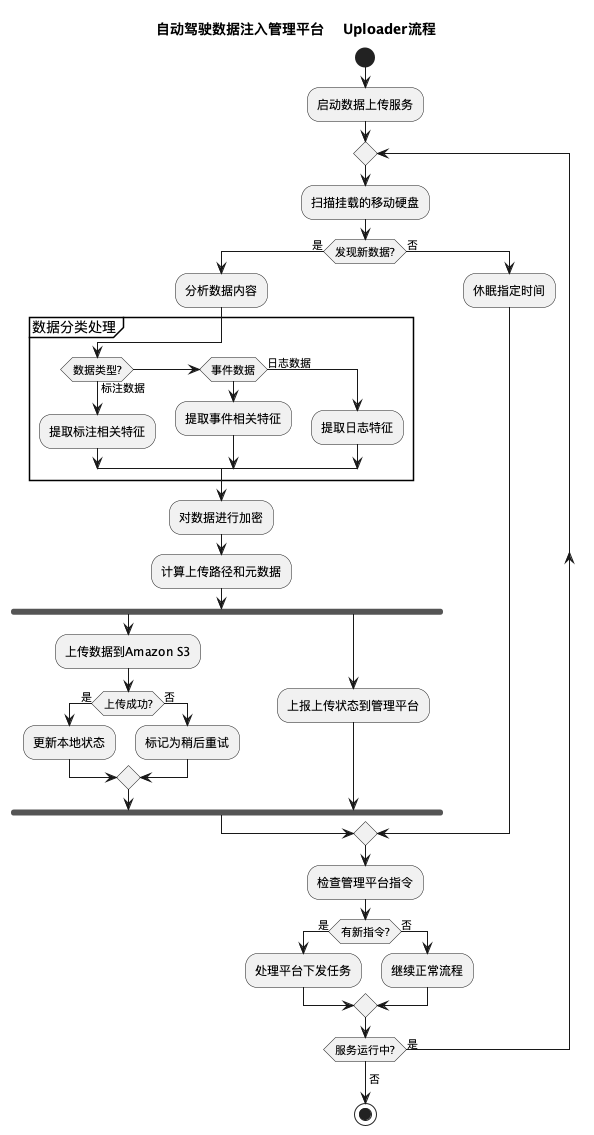
3.2 Uploader端关键功能
- 数据扫描:自动识别移动硬盘中的新数据
- 数据分类:区分标注数据、事件数据和日志数据
- 数据加密:对敏感数据进行加密保护
- 断点续传:支持大文件断点续传和网络中断恢复
- 状态上报:定期向云端API上报设备和任务状态
3.3 Uploader工程结构
主要组件包括:
- 硬盘扫描模块:探测并读取移动硬盘数据
- 数据分析模块:区分数据类型并提取关键特征
- 加密模块:使用安全算法加密数据
- S3上传模块:处理文件上传和元数据管理
- 配置和状态模块:管理配置和监控上传状态
4. 数据解密与索引建立
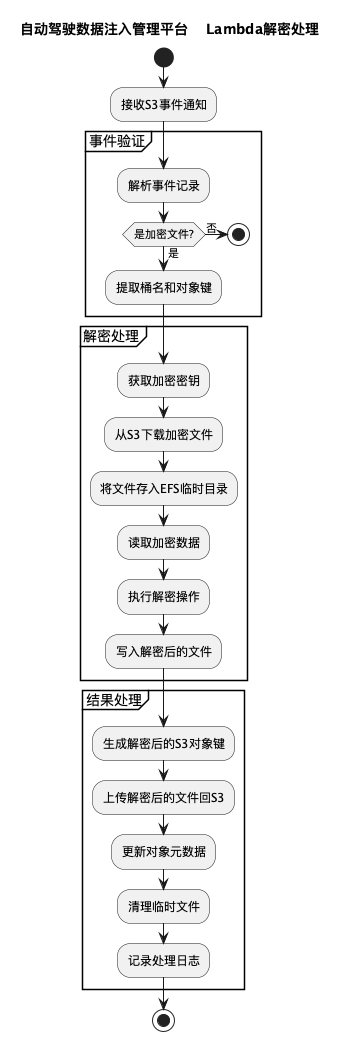
4.1 解密处理流程
当加密数据上传至S3后,通过事件触发机制自动启动解密:
- S3事件通知触发Lambda解密函数
- Lambda函数获取密钥并下载加密文件
- 将文件临时存储在EFS上进行解密
- 解密后文件上传回S3存储桶
4.2 索引建立流程
解密后的数据需要进行分析并建立索引:
- S3事件通知触发Lambda索引函数
- Lambda函数根据文件类型进行分析处理
- 提取关键元数据(如场景类型、对象列表等)
- 构建索引文档并写入ElasticSearch
- 更新S3对象元数据添加索引ID引用

4.3 完整数据流处理
从Uploader上传到最终索引完成的完整流程:
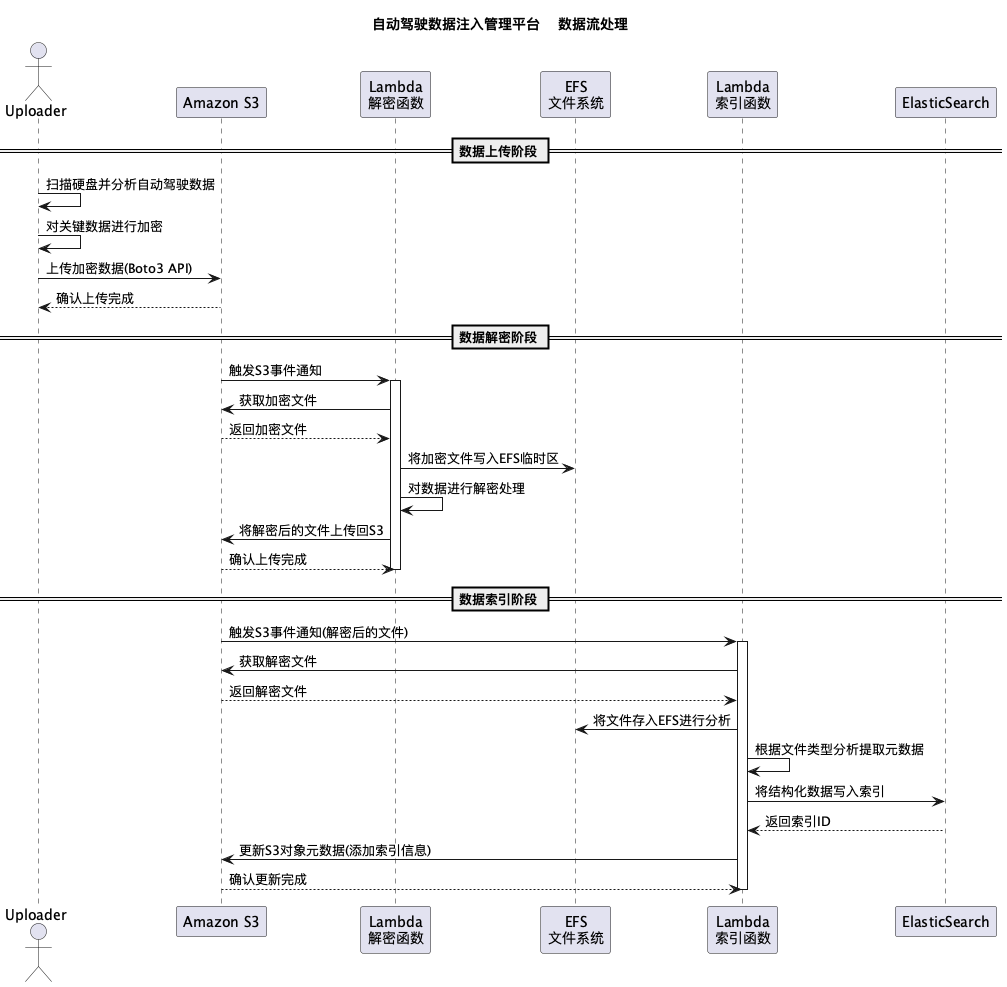
4.4 数据检索示例
研发人员可以通过ElasticSearch的强大检索功能快速查找所需的智能辅助驾驶测试数据。以下是常见检索场景的伪代码示例:
基本场景类型查询
# 查询特定场景类型的数据
def search_by_scene_type(scene_type, limit=10):
query = {
"query": {
"match": {
"scene_type": scene_type # 例如:十字路口、环岛、隧道等
}
},
"size": limit
}
results = elasticsearch_client.search(
index="weride-data",
body=query
)
return format_search_results(results)
多条件复合查询
# 组合多个条件进行复杂查询
def search_complex_conditions(params):
must_conditions = []
# 添加车辆ID条件
if "vehicle_id" in params:
must_conditions.append({
"term": {"vehicle_id": params["vehicle_id"]}
})
# 添加场景对象条件
if "objects" in params:
must_conditions.append({
"terms": {"objects": params["objects"]} # 例如:行人、自行车、卡车等
})
# 添加时间范围条件
if "start_time" in params and "end_time" in params:
must_conditions.append({
"range": {
"timestamp": {
"gte": params["start_time"],
"lte": params["end_time"]
}
}
})
# 添加标签数量条件
if "min_labels" in params:
must_conditions.append({
"range": {
"label_count": {
"gte": params["min_labels"]
}
}
})
query = {
"query": {
"bool": {
"must": must_conditions
}
},
"size": params.get("limit", 20),
"from": params.get("offset", 0)
}
results = elasticsearch_client.search(
index="weride-data",
body=query
)
return format_search_results(results)
地理位置查询
# 基于地理位置搜索特定区域内的数据
def search_by_location(center_lat, center_lon, radius_km, params=None):
must_conditions = [{
"geo_distance": {
"distance": f"{radius_km}km",
"location": {
"lat": center_lat,
"lon": center_lon
}
}
}]
# 添加额外过滤条件
if params and "scene_type" in params:
must_conditions.append({
"match": {"scene_type": params["scene_type"]}
})
if params and "event_type" in params:
must_conditions.append({
"match": {"event_type": params["event_type"]}
})
query = {
"query": {
"bool": {
"must": must_conditions
}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": center_lat,
"lon": center_lon
},
"order": "asc",
"unit": "km"
}
}
],
"size": params.get("limit", 20) if params else 20
}
results = elasticsearch_client.search(
index="weride-data",
body=query
)
return format_search_results(results)
全文搜索
# 全文关键词搜索
def full_text_search(keyword, file_type=None):
query_parts = {
"must": [
{
"multi_match": {
"query": keyword,
"fields": ["search_text", "message_pattern^2", "objects^3"],
"type": "best_fields"
}
}
]
}
# 可选的文件类型过滤
if file_type:
query_parts["filter"] = [{"term": {"file_type": file_type}}]
query = {
"query": {
"bool": query_parts
},
"highlight": {
"fields": {
"search_text": {},
"message_pattern": {}
}
},
"size": 30
}
results = elasticsearch_client.search(
index="weride-data",
body=query
)
return format_search_results(results, include_highlights=True)
结果格式化
# 格式化搜索结果
def format_search_results(results, include_highlights=False):
formatted_results = []
for hit in results["hits"]["hits"]:
result = {
"id": hit["_id"],
"score": hit["_score"],
"file_path": hit["_source"]["file_path"],
"metadata": hit["_source"]
}
# 添加高亮结果(如果有)
if include_highlights and "highlight" in hit:
result["highlights"] = hit["highlight"]
# 获取S3预签名URL供下载
if "file_path" in hit["_source"]:
result["download_url"] = generate_presigned_url(
hit["_source"]["file_path"],
expiration=3600 # 1小时有效期
)
formatted_results.append(result)
return {
"total_hits": results["hits"]["total"]["value"],
"results": formatted_results
}
研发人员可以通过这些API灵活组合检索条件,快速找到所需的测试数据,大大提高了数据利用效率。
5. API网关与安全设计
5.1 API网关实现
基于Amazon API Gateway构建了云端API网关,用于:
- Uploader状态上报
- 配置下发
- 任务管理
- 数据查询和检索
相比最早发布的REST API,选择了2019年发布的HTTP API,提供更好的响应时间和更低的成本。
5.2 双向认证(mTLS)保护
为保障API安全,实现了基于证书的双向TLS认证:
- 给每台Uploader颁发唯一客户端证书
- 在API Gateway启用自定义域名并配置mTLS
- 通过证书而非密码实现设备认证
- 有效防止非授权设备的API访问
这种机制借鉴了IoT设备认证模式,适合无人值守的Uploader设备。
6. 后台管理服务
6.1 容器化后台服务
后台管理服务采用前后端分离架构:
- 前端webserver:提供Web UI界面
- 后端apiserver:处理业务逻辑
原始系统部署在自建Kubernetes集群上,改造后迁移至Amazon ECS+Fargate。
6.2 ECS与Fargate部署优势
迁移到ECS和Fargate带来的好处:
- 无需管理底层EC2实例
- 弹性扩展更加自动化
- 降低运维复杂度
- 按需付费降低成本
6.3 Fargate Spot提高成本效益
引入Fargate Spot提供经济高效的容器运行方式:
- 价格比按需任务低50%-70%
- 使用剩余容量运行容器任务
- 对中断有容错能力的服务更适合使用
- 通过容量提供策略灵活分配资源
6.3.1 Capacity Provider策略配置
具体如何确定多少任务运行在Fargate,多少任务运行在Fargate Spot呢?可以通过Capacity Provider策略来精确控制。
Capacity Provider策略包含以下关键配置:
{
"capacityProviderStrategy": [
{
"capacityProvider": "FARGATE",
"base": 2,
"weight": 1
},
{
"capacityProvider": "FARGATE_SPOT",
"weight": 4
}
]
}
策略参数说明:
- base:基准值,指定在特定容量提供者上必须运行的任务最小数量。一个策略中只有一个容量提供者可以定义基准值。
- weight:权重值,定义使用各容量提供者启动任务的相对比例。
工作原理:
- 首先,ECS会确保满足基准值要求。在上例中,至少2个任务会使用FARGATE运行。
- 其余任务根据权重比例在不同容量提供者间分配。
计算公式:
- 计算权重总和:
weightSum = sum(each provider's weight) - 计算特定提供者的任务比例:
proportion = provider weight / weightSum
示例计算: 假设需要启动6个任务:
- 首先,2个任务分配给FARGATE(基准值)
- 剩余4个任务根据权重比例1:4分配
- FARGATE额外获得4 × (1÷5) = 0.8≈1个任务
- FARGATE_SPOT获得4 × (4÷5) = 3.2≈3个任务
最终分配结果:
- FARGATE: 3个任务
- FARGATE_SPOT: 3个任务
通过这种配置方式,既能保证关键任务的稳定性(通过基准值保证在标准Fargate上运行),又能最大化成本效益(将更多任务分配给价格低廉的Fargate Spot)。
7. 性能与经济效益分析
7.1 性能优势
系统在运行期间展现出以下性能优势:
- Lambda自动扩展,应对峰值流量
- S3高吞吐量满足大量数据上传需求
- ElasticSearch提供高效的数据检索能力
- ECS+Fargate按需扩容,降低资源浪费
7.2 经济效益
Serverless架构为公司带来明显经济效益:
- 按使用量付费,避免资源闲置
- 降低运维人力成本
- 基础设施自动化减少错误和重复工作
- 开发周期缩短,加速业务创新
8. 总结与展望
通过采用Amazon Serverless技术,成功构建了高效、低成本的智能辅助驾驶数据注入管理平台,具有以下特点:
- 高效:通过事件驱动模型实现数据自动化处理
- 安全:采用mTLS等机制确保数据安全和API访问控制
- 弹性:无需预置容量,自动适应业务负载变化
- 低成本:按使用量付费,并通过Spot实例进一步降低成本
- 易运维:简化基础设施管理,专注业务逻辑开发
展望未来,平台还可以在以下方面进一步完善:
- 增强数据分析能力,提供更精准的场景识别
- 集成机器学习能力,实现数据智能分析
- 扩展数据检索接口,支持更复杂的查询需求
- 加强系统监控,提供更全面的健康监测
这个案例展示了如何利用云原生技术实现传统数据处理系统的现代化改造,为智能辅助驾驶领域的数据管理提供了一种高效、经济的解决方案。